

一、存储引擎简介
存储引擎是 MySQL 中具体与文件打交道的子系统,它是根据 MySQL AB 公司提供的文件访问层抽象接口定制的一种文件访问机制,这种机制就叫作存储引擎,下面是一些常用的存储引擎,有远古时期的 MyISAM、支持事务的 InnoDB、内存类型的 Memory、归档类型的 Archive、列式存储的 Infobright,以及一些新兴的存储引擎,以 RocksDB 为底层基础的 MyRocks 和 RocksDB,和以分形树索引组织存储的 TokuDB,当然现在还有极数云舟出品的分布式存储引擎 ArkDB。
在 MySQL 5.6 版本之前,默认的存储引擎都是 MyISAM,但 5.6 版本以后默认的存储引擎就是 InnoDB 了。
1、MySQL支持的存储引擎
mysql> show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| CSV | YES | CSV storage engine | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.00 sec)
1、在文件系统中,MySQL会将每一个数据库保存为数据目录下的一个子目录。创建表时,MySQL会在数据库子目录下创建一个和表同名的.frm文件保存表的定义。
2、MySQL使用文件系统的目录和文件来保存数据库和表的定义,大小写敏感和具体的平台密切相关。在Windows中,大小写是不敏感的;但在类Unix中则大小写敏感。
3、不同的存储引擎保存数据和索引的方式是不同的,但表的定义则是在MySQL的服务层统一处理的。
4、MySQL在5.1及之前的版本中,MyISAM是默认的存储引擎,之后默认的是InnoDB。MyISAM存储引擎不支持事务和行级锁。所以不要再默认使用MyISAM,而应默认使用InnoDB。
5、MySQL内建的其他存储引擎:
- Archive引擎,只支持Insert和Select操作。但支持行级锁和专用的缓冲区
- Blackhole引擎
- CSV引擎,可以将普通的CSV文件作为MySQL的表处理,但这种表不支持索引。CSV引擎可以在数据库运行时拷入或拷出文件。可以将Excel文件存储为CSV文件,然后复制到MySQL数据目录中,就能在MySQL中打开使用。同样,如果将数据写入到一个CSV引擎表,其他的外部程序也能立即从表的数据文件中读取CSV格式的数据。
- Federated引擎,是访问其他MySQL服务器的一个代理,它会创建一个到远程MySQL服务器的客户端连接,并将查询传输到远程服务器执行,然后提取或者发送需要的数据。
- Memory引擎。所有的数据都保存在内存中,Memory表的结构在重启后还是会保留,但数据会丢失。
- Merge引擎。MyISAM引擎的一个变种。Merge表是有多个MyISAM表合并而来的虚拟表
- NDB引擎。MySQL集群的存储引擎。
2、常用存储引擎对比
| 存储引擎 | 优点 | 缺点 |
|---|---|---|
| innoDB | 提供事务的支持,回滚,崩溃修复恢复能力,多版本事务并发控制(默认存储引擎) | 读写效率较差,占用的数据库空间较大 |
| Memory | 内存中对数据创建表,数据全部存储在内存,读写速度非常快,对数据的安全性要求比较低 | 生命周期短 |
| MYISAM | 支持三种存储方式:静态型,动态型,压缩型,占用的空间小,存储的速度快 | 不支持事务和并发 |
| TokuDB | 注重insert性能,压缩比高,数据的插入性能高 | 限制记录不能太大,不注重update的性能 |
InnoDB 和 MyISAM 的功能对比如下图所示。
| 功能 | innoDB | MYISAM |
|---|---|---|
| ACID事务 | 是 | 否 |
| 配置ACID属性 | 是 | 否 |
| 崩溃恢复 | 是 | 否 |
| 外键支持 | 是 | 否 |
| 行级锁力度 | 是 | 否 |
| MVCC | 是 | 否 |
-
InnoDB 支持 ACID 的事务 4 个特性,而 MyISAM 不支持;
-
InnoDB 支持 4 种事务隔离级别,默认是可重复读 Repeatable Read 的,MyISAM 不支持;
-
InnoDB 支持 crash 安全恢复,MyISAM 不支持;
-
InnoDB 支持外键,MyISAM 不支持;
-
InnoDB 支持行级别的锁粒度,MyISAM 不支持,只支持表级别的锁粒度;
-
InnoDB 支持 MVCC,MyISAM 不支持;
InnoDB 表最大还可以支持 64TB,支持聚簇索引、支持压缩数据存储,支持数据加密,支持查询/索引/数据高速缓存,支持自适应hash索引、空间索引,支持热备份和恢复等,如下图所示。
| 功能 | 支持 | 功能 | 支持 |
|---|---|---|---|
| 存储限制 | 64TB | 索引高速缓存 | 是 |
| MVCC | 是 | 数据高速缓存 | 是 |
| B树索引 | 是 | 自适应散列索引 | 是 |
| 群集索引 | 是 | 复制 | 是 |
| 压缩数据 | 是 | 更改数据字典 | 是 |
| 加密数据 | 是 | 地理空间数据类型 | 是 |
| 查询高速缓存 | 是 | 地理空间索引 | 是 |
| 事务 | 是 | 全文搜索索引 | 是 |
| 锁定粒度 | 是 | 群集数据库 | 是 |
| 外键 | 是 | 备份和恢复 | 是 |
| 文件格式管理 | 是 | 快速索引创建 | 是 |
| 多个缓冲区池 | 是 | PERFORMANCE_SCHEMA | 是 |
| 更改换冲 | 是 | 自动故障恢复 | 是 |
二、查看存储引擎
1、查看存储引擎设置
mysql> SELECT @@default_storage_engine;
+--------------------------+
| @@default_storage_engine |
+--------------------------+
| InnoDB |
+--------------------------+
1 row in set (0.00 sec)
2、查看表存储引擎状态
1、查看指定表
mysql> show create table school.test;
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| test | CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '学号',
`sname` varchar(255) NOT NULL COMMENT '姓名',
`age` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '年龄',
`gender` enum('m','f','n') NOT NULL DEFAULT 'n' COMMENT '性别',
`intime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入学时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
2、查看全局表
mysql> select table_schema,table_name ,engine from information_schema.tables where table_schema not in ('sys','mysql','information_schema','performance_schema');
+--------------+-----------------+--------+
| table_schema | table_name | engine |
+--------------+-----------------+--------+
| school | stu | InnoDB |
| school | test | InnoDB |
| test | t100w | InnoDB |
| world | city | InnoDB |
| world | country | InnoDB |
| world | countrylanguage | InnoDB |
+--------------+-----------------+--------+
6 rows in set (0.03 sec)
三、修改存储引擎
1、修改存储引擎
mysql> alter table school.test engine=MyISAM;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table school.test;
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| test | CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '学号',
`sname` varchar(255) NOT NULL COMMENT '姓名',
`age` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '年龄',
`gender` enum('m','f','n') NOT NULL DEFAULT 'n' COMMENT '性别',
`intime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入学时间',
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
2、整理碎片(仅限innodb)
mysql> alter table school.test engine=innodb;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
3、批量替换
批量替换zabbix表存储引擎innodb为tokudb
mysql> select concat("alter table ",table_schema,".",table_name," engine=tokudb;")
from information_schema.tables
where table_schema='zabbix';
四、InnoDB存储引擎物理存储结构
# cd /data/mysql/data/
# ll
总用量 122928
-rw-r----- 1 mysql mysql 56 8月 27 19:00 auto.cnf
drwxr-x--- 2 mysql mysql 20 8月 28 22:16 blog
-rw-r----- 1 mysql mysql 307 8月 29 23:39 ib_buffer_pool
-rw-r----- 1 mysql mysql 12582912 10月 5 13:54 ibdata1
-rw-r----- 1 mysql mysql 50331648 10月 5 13:54 ib_logfile0
-rw-r----- 1 mysql mysql 50331648 10月 4 16:33 ib_logfile1
-rw-r----- 1 mysql mysql 12582912 10月 4 18:01 ibtmp1
drwxr-x--- 2 mysql mysql 4096 8月 27 19:00 mysql
-rw-r----- 1 mysql mysql 7637 8月 29 23:39 mysql-1.err
-rw-r----- 1 mysql mysql 6 8月 30 00:05 mysql-1.pid
drwxr-x--- 2 mysql mysql 8192 8月 27 19:00 performance_schema
drwxr-x--- 2 mysql mysql 82 10月 5 13:54 school
drwxr-x--- 2 mysql mysql 8192 8月 27 19:00 sys
drwxr-x--- 2 mysql mysql 56 10月 4 17:43 test
drwxr-x--- 2 mysql mysql 144 9月 7 09:53 world
| 组件 | 说明 |
|---|---|
| ibdata1 | 系统数据字典信息(统计信息),UNDO表空间等数据 |
| ib_logfile0 ~ ib_logfile1 | REDO日志文件,事务日志文件 |
| ibtmp1 | 临时表空间磁盘位置,存储临时表 |
| frm | 存储表的列信息 |
| ibd | 表的数据行和索引 |
| ib_logfile0 ib_logfile1 | Redo Log,重做日志 |
| ibdata1 | 存储在共享表空间中,回滚日志 |
| ibtmp1 | 临时表,在做join union操作产生临时数据,用完自动清理 |
1、共享表空间
1、查看共享表空间参数设置
初始生成默认大小为12M的共享表空间,当空间不足时自动扩展,每次增加64M
mysql> select @@innodb_data_file_path;
+-------------------------+
| @@innodb_data_file_path |
+-------------------------+
| ibdata1:12M:autoextend |
+-------------------------+
1 row in set (0.01 sec)
mysql> show variables like '%extend%';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| innodb_autoextend_increment | 64 |
+-----------------------------+-------+
1 row in set (0.01 sec)
2、共享表空间自定义设置(MySQL初始化)
初始生成默认大小为512M的共享表空间,当空间不足时自动扩展,每次增加64M,作用是预留足够共享表空间。
# mysqld --initialize-insecure --user=mysql --basedir=xxxxxx..... innodb_data_file_path=ibdata1:512M:ibdata2:512M:autoextend
2、独立表空间
作用: 存储用户数据
特点: 一个表一个ibd文件,存储数据行和索引信息
总结: 一张InnoDB表= frm+idb+ibdata1
1、独立表空间设置
mysql> select @@innodb_file_per_table;
+-------------------------+
| @@innodb_file_per_table |
+-------------------------+
| 1 |
+-------------------------+
mysql> set global innodb_file_per_table=0; //1为开启,0为关闭,默认开启
2、独立表空间迁移
(1)创建和原表结构一致的空表
(2)将空表的ibd文件删除
mysql> alter table 表名 dicard tablespace;
(3)将原表的ibd拷贝过来,并且修改权限
(4)将原表ibd进行导入
mysql> alter table 表名 import tablespace;
3、临时表空间
1、临时表的种类
1、全局临时表
这种临时表从数据库实例启动后开始生效,在数据库实例销毁后失效。在MySQL里面这种临时表对应的是内存表,即memory引擎。
2、会话级别临时表
这种临时表在用户登录系统成功后生效,在用户退出时失效。在MySQL里的临时表指的就是以create temporary table这样的关键词创建的表。
3、事务级别临时表
这种临时表在事务开始时生效,事务提交或者回滚后失效。 在MySQL里面没有这种临时表,必须利用会话级别的临时表间接实现。
4、检索级别临时表
这种临时表在SQL语句执行之间产生,执行完毕后失效。 在MySQL里面这种临时表不是很固定,跟随MySQL默认存储引擎来变化。
比如默认存储引擎是MyISAM,临时表的引擎就是MyISAM,并且文件生成形式以及数据运作形式和MyISAM一样,只是数据保存在内存里;如果默认引擎是INNODB,那么临时表的引擎就是INNODB,此时它的所有信息都保存在共享表空间ibdata里面。
2、MySQL 5.7的临时表空间优化
MySQL 5.7 把临时表的数据以及回滚信息(仅限于未压缩表)从共享表空间里面剥离出来,形成自己单独的表空间,参数为innodb_temp_data_file_path。
在MySQL 5.7 中把临时表的相关检索信息保存在系统信息表中:information_schema.innodb_temp_table_info. 而MySQL 5.7之前的版本想要查看临时表的系统信息是没有太好的办法。
注意:
虽然INNODB临时表有自己的表空间,但是目前还不能自己定义临时表空间文件的保存路径,只能是继承innodb_data_home_dir。此时如果想要拿其他的磁盘,比如内存盘来充当临时表空间的保存地址,只能用老办法,做软链。
3、临时表使用建议
- 设置 innodb_temp_data_file_path 选项,设定文件最大上限,超过上限时,需要生成临时表的SQL无法被执行(一般这种SQL效率也比较低,可借此机会进行优化)。
- 检查 INFORMATION_SCHEMA.INNODB_TEMP_TABLE_INFO,找到最大的临时表对应的线程,kill之即可释放,但 ibtmp1 文件则不能释放(除非重启)。
- 择机重启实例,释放ibtmp1文件,和ibdata1不同,ibtmp1重启时会被重新初始化而 ibdata1 则不可以。
- 定期检查运行时长超过N秒(比如N=300)的SQL,考虑干掉,避免垃圾SQL长时间运行影响业务。
4、临时表的创建
mysql> create temporary table temp1(sid int,sname varchar(10));
Query OK, 0 rows affected (0.00 sec)
mysql> insert into temp1 values(1,'aaa');
Query OK, 1 row affected (0.00 sec)
mysql> select * from temp1;
+------+-------+
| sid | sname |
+------+-------+
| 1 | aaa |
+------+-------+
1 row in set (0.00 sec)
mysql> show tables;
+-----------------+
| Tables_in_test1 |
+-----------------+
| app01 |
| app02 |
| app03 |
+-----------------+
3 rows in set (0.00 sec)
另起一个会话:
mysql> use test1;
Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed
mysql> show tables;
+-----------------+
| Tables_in_test1 |
+-----------------+
| app01 |
| app02 |
| app03 |
+-----------------+
3 rows in set (0.00 sec)
mysql> select * from temp1; ERROR 1146 (42S02): Table 'test1.temp1' doesn't exist
退出本次会话:
mysql> use test1;
Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed
mysql> select * from temp1;
ERROR 1146 (42S02): Table 'test1.temp1' doesn't exist
五、事务(InnoDB引擎)
事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消。也就是事务具有原子性,一个事务中的一系列的操作要么全部成功,要么一个都不做。
事务的结束有两种,当事务中的所以步骤全部成功执行时,事务提交。如果其中一个步骤失败,将发生回滚操作,撤消撤消之前到事务开始时的所以操作。
1、事务的ACID特性
事务具有四个特征:原子性( Atomicity )、一致性( Consistency )、隔离性( Isolation )和持续性( Durability )。这四个特性简称为 ACID 特性。
| 特性 | 说明 |
|---|---|
| Atomic(原子性) | 事务是数据库的逻辑工作单位,事务中包含的各操作要么都做,要么都不做 |
| Consistent(一致性) | 事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。因此当数据库只包含成功事务提交的结果时,就说数据库处于一致性状态。如果数据库系统 运行中发生故障,有些事务尚未完成就被迫中断,这些未完成事务对数据库所做的修改有一部分已写入物理数据库,这时数据库就处于一种不正确的状态,或者说是不一致的状态 |
| Isolated(隔离性) | 一个事务的执行不能其它事务干扰。即一个事务内部的操作及使用的数据对其它并发事务是隔离的,并发执行的各个事务之间不能互相干扰 |
| Durable(持久性) | 也称永久性,指一个事务一旦提交,它对数据库中的数据的改变就应该是永久性的。接下来的其它操作或故障不应该对其执行结果有任何影响 |
2、事务的生命周期
1、开启事务
mysql> begin;
2、标准事务语句
DML语句
insert
update
delete
3、事务结束
1、回滚
mysql> rollback;
2、提交(提交后无法回滚)
mysql> commit;
3、自动提交机制(autocommit)
1、查看参数
mysql> select @@autocommit;
+--------------+
| @@autocommit |
+--------------+
| 1 |
+--------------+
1 row in set (0.00 sec)
2、修改参数(关闭自动提交)
1、会话级别
mysql> set autocommit=0;
2、全局级别
mysql> set global autocommit=0;
3、永久修改(重启生效)
# vim /etc/my.cnf
autocommit=0
4、隐式提交
导致提交的非事务语句:
DDL语句: (ALTER、CREATE 和 DROP)
DCL语句: (GRANT、REVOKE 和 SET PASSWORD)
锁定语句:(LOCK TABLES 和 UNLOCK TABLES)
4、事务的ACID
| 名词 | 解释 |
|---|---|
| redo log | 重做日志,ib_logfile0~1,默认50M , 轮询使用 |
| redo log buffer | redo内存区域,包含数据页的变化信息+数据页当时的LSN号 |
| ibd | 存储 数据行和索引 |
| data buffer pool | 缓冲区池,数据和索引的缓冲 |
| LSN | 日志序列号,存在于ibd,redolog,data buffer pool,redo buffer中 |
| 脏页 | 内存脏页,内存中发生了修改,没写入到磁盘之前,我们把内存页称之为脏页 |
| CKPT | Checkpoint,检查点,就是将脏页刷写到磁盘的动作 |
| TXID | 事务号,InnoDB会为每一个事务生成一个事务号,伴随着整个事务 |
| WAL | write ahead log 日志优先写的方式实现持久化,日志是优先于数据写入磁盘的 |
1、redo 重做日志
功能:
(1)记录了内存数据页的变化.
(2)提供快速的持久化功能(WAL)
(3)CSR过程中实现前滚的操作(磁盘数据页和redo日志LSN一致)
2、undo 回滚日志
作用:
(1)记录了数据修改之前的状态
(2)rollback 将内存的数据修改恢复到修改之前
(3)在CSR中实现未提交数据的回滚操作
(4)实现一致性快照,配合隔离级别保证MVCC,读和写的操作不会互相阻塞
3、锁
锁用独占的方式来保证在只有一个版本的情况下事务之间相互隔离,所以锁可以理解为单版本控制。
在 MySQL 事务中,锁的实现与隔离级别有关系,在 RR(Repeatable Read)隔离级别下,MySQL 为了解决幻读的问题,以牺牲并行度为代价,通过 Gap 锁来防止数据的写入,而这种锁,因为其并行度不够,冲突很多,经常会引起死锁。现在流行的 Row 模式可以避免很多冲突甚至死锁问题,所以推荐默认使用 Row + RC(Read Committed)模式的隔离级别,可以很大程度上提高数据库的读写并行度。
在 MySQL 中有三种级别的锁:页级锁、表级锁、行级锁。
-
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。 会发生在:MyISAM、memory、InnoDB、BDB 等存储引擎中。
-
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度最高。会发生在:InnoDB 存储引擎。
-
页级锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。会发生在:BDB 存储引擎。
三种级别的锁分别对应存储引擎关系如下图所示。
| 行锁 | 表锁 | 页锁 | |
|---|---|---|---|
| MyISAM | √ | ||
| BDB | √ | √ | |
| InnoDB | √ | √ |
注意:MySQL 中的表锁包括读锁和写锁。
4、隔离级别
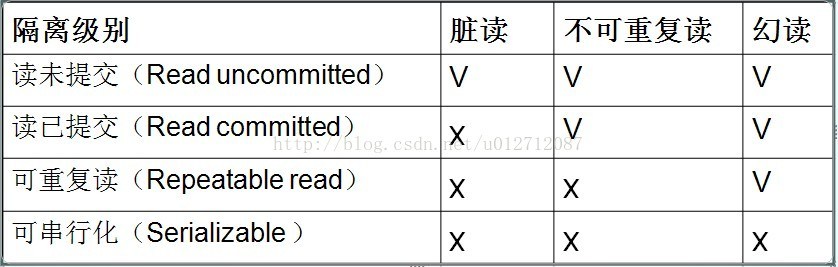
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
| 级别 | 说明 |
|---|---|
| Read Uncommitted(读取未提交内容) | 在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read) |
| Read Committed(读取提交内容) | 这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。 |
| Repeatable Read(可重读) | 这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。 |
| Serializable(可串行化) | 这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。可串行化,可以防止死锁,但是并发事务性能较差 |
这四种隔离级别采取不同的锁类型来实现,若读取的是同一个数据的话,就容易发生问题。例如:
- 脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
- 不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
- **幻读(Phantom Read):**在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
在RC级别下可以减轻GAP+NextLock锁的问题,但是会出现幻读现象,一般在为了读一致性会在正常select后添加for update语句,但是执行完一定要commit,否则容易出现所等待比较严重。
1、查看数据库隔离级别
# mysql -uroot -p1
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set, 1 warning (0.00 sec)
2、更改隔离级别方法
1、 服务器启动时设置级别。
# vim /etc/my.cnf
#服务端配置
[mysqld]
transaction-isolation = [SERIALIZABLE |READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ ]
2、使用SET TRANSACTION ISOLATION LEVEL语句为正在运行的服务器设置。
# 设置全局级别默认事务隔离级别,适用于从设置时起所有新建立的客户机连接。现有连接不受影响。
SET GLOBAL TRANSACTION ISOLATION LEVEL [SERIALIZABLE |READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ ] ;
#设置会话级别默认事务隔离级别,如果没有显式指定,则事务隔离级别将按会话进行设置,应用于当前session内之后的所有事务。
SET SESSION TRANSACTION ISOLATION LEVEL [SERIALIZABLE |READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ ];
#适用于当前session内的下一个还未开始的事务
SET TRANSACTION ISOLATION LEVEL [SERIALIZABLE |READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ ];
5、InnoDB核心参数
1、存储引擎默认设置
default_storage_engine=innodb
2、表空间模式
innodb_file_per_table=1
3、共享表空间文件个数和大小
innodb_data_file_path=ibdata1:512M:ibdata2:512M:autoextend
4、“双一” 标准
innodb_flush_log_at_trx_commit=1
-------
The default setting of 1 is required for full ACID compliance. Logs are written and flushed to disk at each transaction commit.
With a setting of 0, logs are written and flushed to disk once per second. Transactions for which logs have not been flushed can be lost in a crash.
With a setting of 2, logs are written after each transaction commit and flushed to disk once per second. Transactions for which logs have not been flushed can be lost in a crash.
-------
翻译:为了完全符合ACID,默认设置为1是必需的。在每个事务提交时,日志被写入并刷新到磁盘。
如果设置为0,那么日志将每秒写入一次并刷新到磁盘。未为其刷新日志的事务可能会在崩溃中丢失。
如果设置为2,则在每个事务提交后写入日志,并每秒刷新到磁盘一次。未为其刷新日志的事务可能会在崩溃中丢失。
控制 Redo buffer 和 buffer pool
Innodb_flush_method=(O_DIRECT,fsync)
| 参数 | 说明 |
|---|---|
| fsync | 最高性能 |
| O_DIRECT | 注重安全 |
| 最高安全模式 |
innodb_flush_log_at_trx_commit=1
Innodb_flush_method=O_DIRECT
最高性能
innodb_flush_log_at_trx_commit=0
Innodb_flush_method=fsync
5、redo日志设置相关
innodb_log_buffer_size=16777216 //日志缓冲区大小
innodb_log_file_size=50331648 //日志大小(默认50M)
innodb_log_files_in_group = 3 //redo个数(默认2个),即ib_logfile
6、脏页刷写策略
innodb_max_dirty_pages_pct=75 //脏页占用内存比达到75%时写入磁盘
5、多版本并发控制MVCC
多版本控制也叫作 MVCC,是指在数据库中,为了实现高并发的数据访问,对数据进行多版本处理,并通过事务的可见性来保证事务能看到自己应该看到的数据版本。
那个多版本是如何生成的呢?每一次对数据库的修改,都会在 Undo 日志中记录当前修改记录的事务号及修改前数据状态的存储地址(即 ROLL_PTR),以便在必要的时候可以回滚到老的数据版本。例如,一个读事务查询到当前记录,而最新的事务还未提交,根据原子性,读事务看不到最新数据,但可以去回滚段中找到老版本的数据,这样就生成了多个版本。
多版本控制很巧妙地将稀缺资源的独占互斥转换为并发,大大提高了数据库的吞吐量及读写性能。
1、MVCC的实现是通过保存数据在某个时间点的快照来实现。
2、不同存储引擎的MVCC实现是不同的。典型的有乐观(optimistic)控制和悲观(pessimistic)控制
3、MVCC只在REPEATABLE READ 和READ COMMITTED两个隔离级别下工作。
其他两个隔离级别都不和MVCC兼容。是因为,READ UNCOMMITED总是读取最新的数据行,而不是读取符合当前事务版本的数据行,而SERIALIZABLE则会在所有读取的行都加锁。
4、InnoDB的MVCC通过在每行记录后面保存两个隐藏的列来实现的,一列保存了行的创建时间,一列保存行的过期时间(或删除时间),存储的并不是实际的时间值,而是系统版本号(System Version Number)。没开始一个新的事务,系统版本号会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行对比。
评论区