

持久化是 最简单的 高可用方法。它的主要作用是 数据备份,即将数据存储在 硬盘,保证数据不会因进程退出而丢失。
Redis 提供了两种持久化方式:
RDB 快照(snapshot)- 将存在于某一时刻的所有数据都写入到硬盘中。只追加文件(append-only file,AOF)- 它会在执行写命令时,将被执行的写命令复制到硬盘中。
这两种持久化方式既可以同时使用,也可以单独使用。
将内存中的数据存储到硬盘的一个主要原因是为了在之后重用数据,或者是为了防止系统故障而将数据备份到一个远程位置。另外,存储在 Redis 里面的数据有可能是经过长时间计算得出的,或者有程序正在使用 Redis 存储的数据进行计算,所以用户会希望自己可以将这些数据存储起来以便之后使用,这样就不必重新计算了。
Redis 提供了两种持久方式:RDB 和 AOF,默认采用的是RDB的方式。你可以同时开启两种持久化方式。在这种情况下, 当 redis 重启的时候会优先载入 AOF 文件来恢复原始的数据,因为在通常情况下 AOF 文件保存的数据集要比 RDB 文件保存的数据集要完整。
一、RDB
1、RDB 简介
RDB 即快照方式,它将某个时间点的所有 Redis 数据保存到一个经过压缩的二进制文件(RDB 文件)中。
创建 RDB 后,用户可以对 RDB 进行备份,可以将 RDB 复制到其他服务器从而创建具有相同数据的服务器副本,还可以在重启服务器时使用。一句话来说:RDB 适合作为 冷备。
RDB 既可以手动执行,也可以根据服务器配置选项定期执行。该功能可以将某个时间点的数据库状态保存到一个 RDB 文件中。
2、RDB 的优点
- RDB 文件非常紧凑,适合作为冷备。比如你可以在每个小时报保存一下过去 24 小时内的数据,同时每天保存过去 30 天的数据,这样即使出了问题你也可以根据需求恢复到不同版本的数据集。
- 快照在保存 RDB 文件时父进程唯一需要做的就是 fork 出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他 IO 操作,所以快照持久化方式可以最大化 Redis 的性能。
- 恢复大数据集时,RDB 比 AOF 更快。
3、RDB 的缺点
- 如果系统发生故障,将会丢失最后一次创建快照之后的数据。如果你希望在 Redis 意外停止工作(例如电源中断)的情况下丢失的数据最少的话,那么 快照不适合你。虽然你可以配置不同的 save 时间点(例如每隔 5 分钟并且对数据集有 100 个写的操作),是 Redis 要完整的保存整个数据集是一个比较繁重的工作,你通常会每隔 5 分钟或者更久做一次完整的保存,万一在 Redis 意外宕机,你可能会丢失几分钟的数据。
- 如果数据量很大,保存快照的时间会很长。快照需要经常 fork 子进程来保存数据集到硬盘上。当数据集比较大的时候,fork 的过程是非常耗时的,可能会导致 Redis 在一些毫秒级内不能响应客户端的请求。如果数据集巨大并且 CPU 性能不是很好的情况下,这种情况会持续 1 秒。AOF 也需要 fork,但是你可以调节重写日志文件的频率来提高数据集的耐久度。
2、RDB 的创建
有两个 Redis 命令可以用于生成 RDB 文件:SAVE 和 BGSAVE。
SAVE命令会阻塞 Redis 服务器进程,直到 RDB 创建完成为止,在阻塞期间,服务器不能响应任何命令请求。BGSAVE命令会派生出(fork)一个子进程,然后由子进程负责创建 RDB 文件,服务器进程(父进程)继续处理命令请求。
注意:BGSAVE 命令执行期间,SAVE、BGSAVE、BGREWRITEAOF 三个命令会被拒绝,以免与当前的 BGSAVE 操作产生竞态条件,降低性能。
1、自动间隔保存
Redis 允许用户通过设置服务器配置的 save 选项,让服务器每隔一段时间自动执行一次 BGSAVE 命令。
用户可以通过 save 选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会执行 BGSAVE 命令。
举例来说,redis.conf 中设置了如下配置:
save 900 1 -- 900 秒内,至少对数据库进行了 1 次修改
save 300 10 -- 300 秒内,至少对数据库进行了 10 次修改
save 60 10000 -- 60 秒内,至少对数据库进行了 10000 次修改
只要满足以上任意条件,Redis 服务就会执行 BGSAVE 命令。
3、RDB 的载入
RDB 文件的载入工作是在服务器启动时自动执行的,Redis 并没有专门用于载入 RDB 文件的命令。
服务器载入 RDB 文件期间,会一直处于阻塞状态,直到载入完成为止。
🔔 注意:因为 AOF 通常更新频率比 RDB 高,所以丢失数据相对更少。基于这个原因,Redis 有以下默认行为:
- 只有在关闭 AOF 功能的情况下,才会使用 RDB 还原数据,否则优先使用 AOF 文件来还原数据。
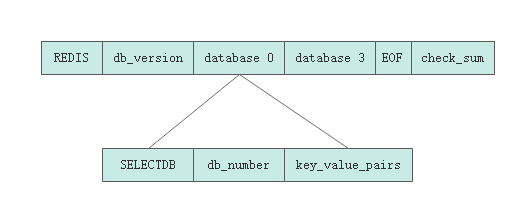
4、RDB 的文件结构
RDB 文件是一个经过压缩的二进制文件,由多个部分组成。
对于不同类型(STRING、HASH、LIST、SET、SORTED SET)的键值对,RDB 文件会使用不同的方式来保存它们。
Redis 本身提供了一个 RDB 文件检查工具 redis-check-dump。
5、RDB 的配置
Redis RDB 默认配置如下:
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir ./
Redis 的配置文件 redis.conf 中与 RDB 有关的选项:
-
save- Redis 会根据save选项,让服务器每隔一段时间自动执行一次BGSAVE命令。 -
stop-writes-on-bgsave-error- 当 BGSAVE 命令出现错误时停止写 RDB 文件 -
rdbcompression- RDB 文件开启压缩功能。 -
rdbchecksum- 对 RDB 文件进行校验。 -
dbfilename- RDB 文件名。 -
dir- RDB 文件和 AOF 文件的存储路径。
二、AOF
1、AOF 简介
AOF(Append Only File) 是以 文本日志形式 将 所有写命令以 Redis 命令请求协议格式追加到 AOF 文件的末尾,以此来记录数据的变化。当服务器重启时,会重新载入和执行 AOF 文件中的命令,就可以恢复原始的数据。AOF 适合作为 热备。
AOF 可以通过 appendonly yes 配置选项来开启。
命令请求会先保存到 AOF 缓冲区中,之后再定期写入并同步到 AOF 文件。
1、AOF 的优点
- 如果系统发生故障,AOF 丢失数据比 RDB 少。你可以使用不同的 fsync 策略:无 fsync;每秒 fsync;每次写的时候 fsync。使用默认的每秒 fsync 策略,Redis 的性能依然很好(fsync 是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失 1 秒的数据。
- AOF 文件可修复 - AOF 文件是一个只进行追加的日志文件,所以不需要写入 seek,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也也可使用 redis-check-aof 工具修复这些问题。
- AOF 文件可压缩。Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写:重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
- AOF 文件可读 - AOF 文件有序地保存了对数据库执行的所有写入操作,这些写入操作以 Redis 命令的格式保存。因此 AOF 文件的内容非常容易被人读懂,对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单。举个例子,如果你不小心执行了 FLUSHALL 命令,但只要 AOF 文件未被重写,那么只要停止服务器,移除 AOF 文件末尾的 FLUSHALL 命令,并重启 Redis ,就可以将数据集恢复到 FLUSHALL 执行之前的状态。
2、AOF 的缺点
- AOF 文件体积一般比 RDB 大 - 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
- 恢复大数据集时,AOF 比 RDB 慢。 - 根据所使用的 fsync 策略,AOF 的速度可能会慢于快照。在一般情况下,每秒 fsync 的性能依然非常高,而关闭 fsync 可以让 AOF 的速度和快照一样快,即使在高负荷之下也是如此。不过在处理巨大的写入载入时,快照可以提供更有保证的最大延迟时间(latency)。
2、AOF 的创建
Redis 命令请求会先保存到 AOF 缓冲区,再定期写入并同步到 AOF 文件。
AOF 的实现可以分为命令追加(append)、文件写入、文件同步(sync)三个步骤。
- 命令追加 - 当 Redis 服务器开启 AOF 功能时,服务器在执行完一个写命令后,会以 Redis 命令协议格式将被执行的写命令追加到 AOF 缓冲区的末尾。
- 文件写入和文件同步 - Redis 的服务器进程就是一个事件循环,这个循环中的文件事件负责接收客户端的命令请求,以及向客户端发送命令回复。而时间事件则负责执行定时运行的函数。因为服务器在处理文件事件时可能会执行写命令,这些写命令会被追加到 AOF 缓冲区,服务器每次结束事件循环前,都会根据
appendfsync选项来判断 AOF 缓冲区内容是否需要写入和同步到 AOF 文件中。
appendfsync 不同选项决定了不同的持久化行为:
always- 将缓冲区所有内容写入并同步到 AOF 文件。everysec- 将缓冲区所有内容写入到 AOF 文件,如果上次同步 AOF 文件的时间距离现在超过一秒钟,那么再次对 AOF 文件进行同步,这个同步操作是有一个线程专门负责执行的。no- 将缓冲区所有内容写入到 AOF 文件,但并不对 AOF 文件进行同步,何时同步由操作系统决定。
3、AOF 的载入
因为 AOF 文件中包含了重建数据库所需的所有写命令,所以服务器只要载入并执行一遍 AOF 文件中保存的写命令,就可以还原服务器关闭前的数据库状态。
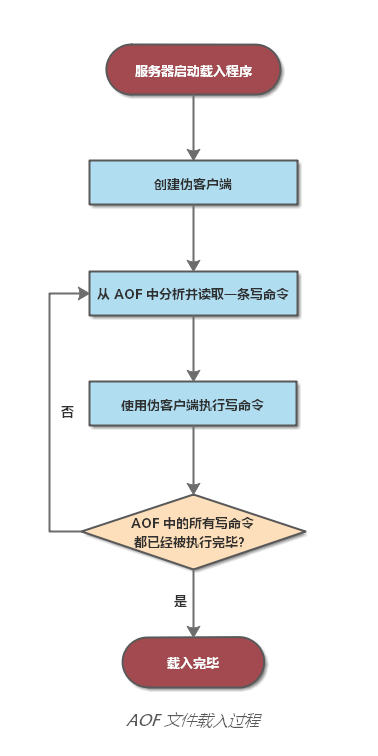
AOF 载入过程如下:
- 服务器启动载入程序。
- 创建一个伪客户端。因为 Redis 命令只能在客户端上下文中执行,所以需要创建一个伪客户端来载入、执行 AOF 文件中记录的命令。
- 从 AOF 文件中分析并读取一条写命令。
- 使用伪客户端执行写命令。
- 循环执行步骤 3、4,直到所有写命令都被处理完毕为止。
- 载入完毕。
4、AOF 的重写
随着 Redis 不断运行,AOF 的体积也会不断增长,这将导致两个问题:
- AOF 耗尽磁盘可用空间。
- Redis 重启后需要执行 AOF 文件记录的所有写命令来还原数据集,如果 AOF 过大,则还原操作执行的时间就会非常长。
为了解决 AOF 体积膨胀问题,Redis 提供了 AOF 重写功能,来对 AOF 文件进行压缩。AOF 重写可以产生一个新的 AOF 文件,这个新的 AOF 文件和原来的 AOF 文件所保存的数据库状态一致,但体积更小。
AOF 重写并非读取和分析现有 AOF 文件的内容,而是直接从数据库中读取当前的数据库状态。即依次读取数据库中的每个键值对,然后用一条命令去记录该键值对,以此代替之前可能存在冗余的命令。
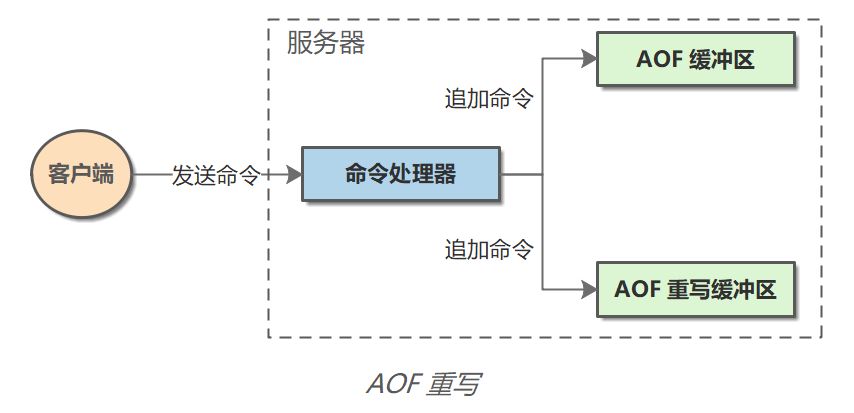
AOF 后台重写
作为一种辅助性功能,显然 Redis 并不想在 AOF 重写时阻塞 Redis 服务接收其他命令。因此,Redis 决定通过 BGREWRITEAOF 命令创建一个子进程,然后由子进程负责对 AOF 文件进行重写,这与 BGSAVE 原理类似。
- 在执行
BGREWRITEAOF命令时,Redis 服务器会维护一个 AOF 重写缓冲区。当 AOF 重写子进程开始工作后,Redis 每执行完一个写命令,会同时将这个命令发送给 AOF 缓冲区和 AOF 重写缓冲区。 - 由于彼此不是在同一个进程中工作,AOF 重写不影响 AOF 写入和同步。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新旧两个 AOF 文件所保存的数据库状态一致。
- 最后,服务器用新的 AOF 文件替换就的 AOF 文件,以此来完成 AOF 重写操作。
可以通过设置 auto-aof-rewrite-percentage 和 auto-aof-rewrite-min-size,使得 Redis 在满足条件时,自动执行 BGREWRITEAOF。
假设配置如下:
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
表明,当 AOF 大于 64MB,且 AOF 体积比上一次重写后的体积大了至少 100% 时,执行 BGREWRITEAOF。
5、AOF 的配置
AOF 的默认配置:
appendonly no
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
AOF 持久化通过在 redis.conf 中的 appendonly yes 配置选项来开启。
appendonly- 开启 AOF 功能。appendfilename- AOF 文件名。appendfsync- 用于设置同步频率,它有以下可选项:always- 每个 Redis 写命令都要同步写入硬盘。这样做会严重降低 Redis 的速度。everysec- 每秒执行一次同步,显示地将多个写命令同步到硬盘。为了兼顾数据安全和写入性能,推荐使用appendfsync everysec选项。Redis 每秒同步一次 AOF 文件时的性能和不使用任何持久化特性时的性能相差无几。no- 让操作系统来决定应该何时进行同步。
no-appendfsync-on-rewrite- AOF 重写时不支持追加命令。auto-aof-rewrite-percentage- AOF 重写百分比。auto-aof-rewrite-min-size- AOF 重写文件的最小大小。dir- RDB 文件和 AOF 文件的存储路径。
三、RDB 和 AOF
当 Redis 启动时, 如果 RDB 和 AOF 功能都开启了,那么程序会优先使用 AOF 文件来恢复数据集,因为 AOF 文件所保存的数据通常是最完整的。
1、如何选择持久化
- 如果不关心数据丢失,可以不持久化。
- 如果可以承受数分钟以内的数据丢失,可以只使用 RDB。
- 如果不能承受数分钟以内的数据丢失,可以同时使用 RDB 和 AOF。
有很多用户都只使用 AOF 持久化, 但并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份,并且快照恢复数据集的速度也要比 AOF 恢复的速度要快,除此之外,使用快照还可以避免之前提到的 AOF 程序的 bug 。
2、RDB 切换为 AOF
在 Redis 2.2 或以上版本,可以在不重启的情况下,从 RDB 切换为 AOF :
- 为最新的 dump.rdb 文件创建一个备份。
- 将备份放到一个安全的地方。
- 执行以下两条命令:
- redis-cli config set appendonly yes
- redis-cli config set save
- 确保写命令会被正确地追加到 AOF 文件的末尾。
- 执行的第一条命令开启了 AOF 功能: Redis 会阻塞直到初始 AOF 文件创建完成为止, 之后 Redis 会继续处理命令请求, 并开始将写入命令追加到 AOF 文件末尾。
执行的第二条命令用于关闭快照功能。 这一步是可选的, 如果你愿意的话, 也可以同时使用快照和 AOF 这两种持久化功能。
:bell: 重要:别忘了在
redis.conf中打开 AOF 功能!否则的话,服务器重启之后,之前通过 CONFIG SET 设置的配置就会被遗忘,程序会按原来的配置来启动服务器。
3、AOF 和 RDB 的相互作用
BGSAVE 和 BGREWRITEAOF 命令不可以同时执行。这是为了避免两个 Redis 后台进程同时对磁盘进行大量的 I/O 操作。
如果 BGSAVE 正在执行,并且用户显示地调用 BGREWRITEAOF 命令,那么服务器将向用户回复一个 OK 状态,并告知用户,BGREWRITEAOF 已经被预定执行。一旦 BGSAVE 执行完毕, BGREWRITEAOF 就会正式开始。
4、持久化文件加载规则
- 如果只开启了 AOF 持久化,Redis 启动时只会加载 AOF 文件(appendonly.aof),进行数据恢复;
- 如果只开启了 RDB 持久化,Redis 启动时只会加载 RDB 文件(dump.rdb),进行数据恢复;
- 如果同时开启了 RDB 和 AOF 持久化,Redis 启动时只会加载 AOF 文件(appendonly.aof),进行数据恢复。
在 AOF 开启的情况下,即使 AOF 文件不存在,只有 RDB 文件,也不会加载 RDB 文件。
5、混合持久化策略
-
RDB 和 AOF 持久化各有利弊,RDB 可能会导致一定时间内的数据丢失,而 AOF 由于文件较大则会影响 Redis 的启动速度,为了能同时使用 RDB 和 AOF 各种的优点,Redis 4.0 之后新增了混合持久化的方式。
-
混合持久化本质是通过 AOF 后台重写(bgrewriteaof 命令)完成的,不同的是当开启混合持久化时,fork 出的子进程先将当前全量数据以 RDB 方式写入新的 AOF 文件,然后再将 AOF 重写缓冲区(aof_rewrite_buf_blocks)的增量命令以 AOF 方式写入到文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
1、混合持久化的加载流程
① 判断是否开启 AOF 持久化,开启继续执行后续流程,未开启执行加载 RDB 文件的流程;
② 判断 appendonly.aof 文件是否存在,文件存在则执行后续流程;
③ 判断 AOF 文件开头是 RDB 的格式, 先加载 RDB 内容再加载剩余的 AOF 内容;
④ 判断 AOF 文件开头不是 RDB 的格式,直接以 AOF 格式加载整个文件。
2、配置
-
在Redis 配置文件中开起
aof-use-rdb-preamble yes -
通过命令行开启
config set aof-use-rdb-preamble yes
4、混合持久化优缺点
-
优点
- 混合持久化结合了 RDB 和 AOF 持久化的优点,开头为 RDB 的格式,使得 Redis 可以更快的启动,同时结合 AOF 的优点,有减低了大量数据丢失的风险。
-
缺点
-
AOF 文件中添加了 RDB 格式的内容,使得 AOF 文件的可读性变得很差;
-
兼容性差,如果开启混合持久化,那么此混合持久化 AOF 文件,就不能用在 Redis 4.0 之前版本了。
-
四、Redis 备份
1、RDB备份
应该确保 Redis 数据有完整的备份。
备份 Redis 数据建议采用 RDB。
1、备份方案
1、写crontab定时调度脚本去数据备份
2、每消失都copy一个rdb的备份到一个目录中去,仅仅保留最近48小时的备份。
3、每天保存一份当天的rdb备份文件到一个目录中去,仅仅保留最近一个月的备份。
4、每次copy备份时将太旧的备份都删了。
5、每天晚上将当前服务器备份的数据发送一份到远程云服务器上。
2、备份过程
1、创建一个定期任务(cron job),每小时将一个 RDB 文件备份到一个文件夹,并且每天将一个 RDB 文件备份到另一个文件夹。
2、确保快照的备份都带有相应的日期和时间信息,每次执行定期任务脚本时,使用 find 命令来删除过期的快照:比如说,你可以保留最近 48 小时内的每小时快照,还可以保留最近一两个月的每日快照。
3、至少每天一次,将 RDB 备份到你的数据中心之外,或者至少是备份到你运行 Redis 服务器的物理机器之外。
3、容灾备份
1、如果是redis进程挂掉,那么重启redis进程积极OK了,直接基于AOF文件进行恢复数据(AOF 配置 fsync everysec 最多丢一秒的数据)
2、如果是Redis所在进程的服务器挂了,重启服务器后尝试重启Redis进程,尝试直接基于AOF日志文件进行数据恢复。
AOF 文件没有损坏直接恢复就可以了,同样最多丢失一秒的数据,如果AOF文件损坏,使用redis-check-aof-fix进行修复后恢复。
3、如果redis当前最新的AOF和RDB文件出现了丢失/损坏(一般认为导致的),那么可以尝试基于该机器上当前的某个最新的RDB数据副本进行数据恢复。
::: warning
基于副本恢复顺序, shutdown ---> copy dump.rdb文件到/var/redis/6379/ (持久化文件存放位置,具体根据conf文件中配置)下面 ---> 修改配置文件暂时关闭AOF配置 ---> 重启redis实例 ---> 临时打开AOF的配置(config set appendonly yes)---> 修改配置文件到开AOF的配置 ---> 重启redis实例--->搞定
:::
4、如果当前机器上的所有RDB文件全部损坏,那么从远程的云服务上拉取最新的RDB快照回来恢复数据
5、如果是发现有重大的数据错误,比如某个小时上线的程序一下子将数据全部污染了,数据全错了,那么可以选择某个更早的时间点,对数据进行恢复
举个例子,12点上线了代码,发现代码有bug,导致代码生成的所有的缓存数据,写入redis,全部错了
找到一份11点的rdb的冷备,然后按照上面的步骤,去恢复到11点的数据,不就可以了吗
3、备份脚本
新建存放备份目录
mkdir /usr/local/redis
每小时copy一次备份,删除48小时之前的数据
crontabl -e
0 * * * * sh /usr/local/redis/copy/redis_rdb_copy_hourly.sh
redis_rdb_copy_hourly.sh
#!/bin/sh
cur_date=`date +%Y%m%d%k`
rm -rf /usr/local/redis/snapshotting/$cur_date
mkdir /usr/local/redis/snapshotting/$cur_date
cp /var/redis/6379/dump.rdb /usr/local/redis/snapshotting/$cur_date
del_date=`date -d -48hour +%Y%m%d%k`
rm -rf /usr/local/redis/snapshotting/$del_date
每天copy一次备份,并删除一个月以前的数据
crontabl -e
0 * * * * sh /usr/local/redis/copy/redis_rdb_copy_daily.sh
redis_rdb_copy_daily.sh
#!/bin/sh
cur_date=`date +%Y%m%d`
rm -rf /usr/local/redis/snapshotting/$cur_date
mkdir /usr/local/redis/snapshotting/$cur_date
cp /var/redis/6379/dump.rdb /usr/local/redis/snapshotting/$cur_date
del_date=`date -d -1month +%Y%m%d`
rm -rf /usr/local/redis/snapshotting/$del_date
每天将当天的所有数据上传一份到远程云服务器上去备份。
2、Redis-dump 备份
Redis-dump Github:https://github.com/delano/redis-dump
1、安装
yum inatll -y ruby
gem sources --add https://mirrors.aliyun.com/rubygems/
gem sources --remove https://rubygems.org/
gem sources --list
# gem安装redis需要ruby版本高于2.3.0,CentOS7默认安装的ruby版本为2.0.0,所以先升级Ruby
gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB
curl -sSL https://get.rvm.io | bash -s stable
source /etc/profile.d/rvm.sh
rvm -v
rvm list known
rvm install 2.5
ruby -V
gem install redis-dump -V
source /etc/profile
redis-dump -V
2、redis-dump导出数据到JSON
Usage: redis-dump [global options] COMMAND [command options]
-u, --uri=S Redis URI (e.g. redis://hostname[:port])
-d, --database=S Redis database (e.g. -d 15)
-a, --password=S Redis password (e.g. -a 'my@pass/word')
-s, --sleep=S Sleep for S seconds after dumping (for debugging)
-c, --count=S Chunk size (default: 10000)
-f, --filter=S Filter selected keys (passed directly to redis' KEYS command)
-b, --base64 Encode key values as base64 (useful for binary values)
-O, --without_optimizations Disable run time optimizations
-V, --version Display version
-D, --debug
--nosafe
示例
redis-dump -u redis://127.0.0.1:6379 -d 0 -c 50000 > redis-backup-$(date "+%Y%m%d").json
3、redis-load导入JSON数据文件到Redis
redis-load [global options] COMMAND [command options]
-u, --uri=S Redis URI (e.g. redis://hostname[:port])
-d, --database=S Redis database (e.g. -d 15)
-a, --password=S Redis password (e.g. -a 'my@pass/word')
-s, --sleep=S Sleep for S seconds after dumping (for debugging)
-b, --base64 Decode key values from base64 (used with redis-dump -b)
-n, --no_check_utf8
-V, --version Display version
-D, --debug
--nosafe
示例
cat redis-backup.json| redis-load -u redis://127.0.0.1:6379 -d 0
注意:相同的Key,值会被覆盖
3、使用redis-cli命令的pipe模式导入
redis在2.6版本推出了一个新的功能pipe mode,即将支持Redis协议的文本文件直接通过pipe导入到服务端。
需要导入的数据格式是redis-cli里可执行的命令。如果想把redis-dump导出的JSON格式数据转换成可导入的数据,参照第三章
seq -f "SET %g test" 2 100000 > data.txt
cat data.txt | redis-cli -n 1 --pipe
4、redis-dump导出数据转换为redis命令格式数据
cat redis-backup-$(date "+%Y%m%d").json |jq -r "\"set \(.key) '\(.value)' EX \(.ttl)\""
评论区