

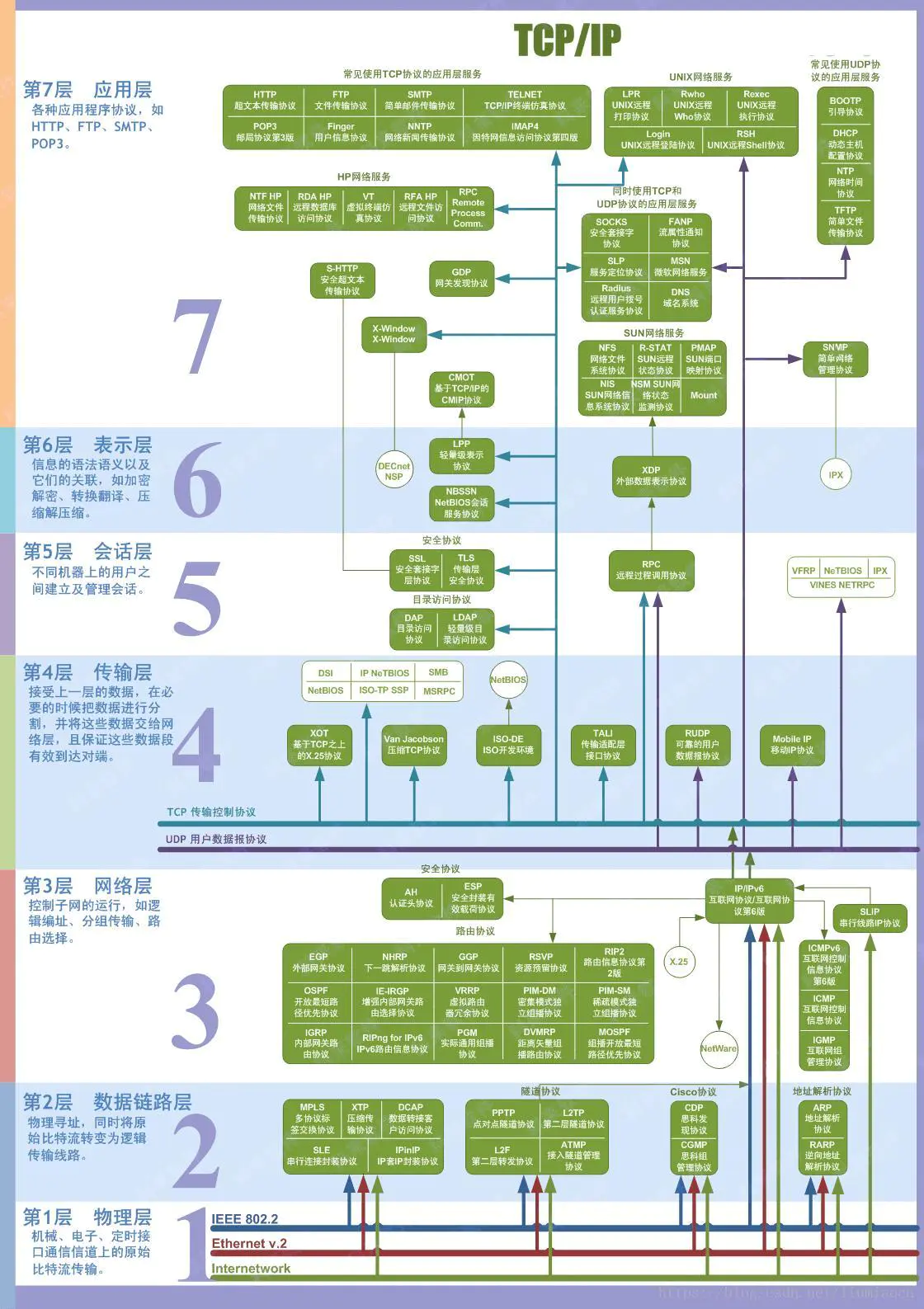
1、OSI七层模型和TCP/IP模型及对应协议
七层模型,亦称OSI(Open System Interconnection)。参考模型是国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系,一般称为OSI参考模型或七层模型。它是一个七层的、抽象的模型体,不仅包括一系列抽象的术语或概念,也包括具体的协议。
| OSI七层模型 | 基本作用 | |
|---|---|---|
| Application Layer | 应用层 | 为应用程序提供网络服务 |
| Presentation Layer | 表示层 | 数据格式化,加密、解密 |
| Session Layer | 会话层 | 建立、维护、管理会话连接 |
| Transport Layer | 传输层 | 建立、维护、管理端到端连接 |
| Network Layer | 网络层 | IP寻址和路由选择 |
| Data Link Layer | 数据链路层 | 控制网络层与物理层之间的通信 |
| Physical Layer | 物理层 | 比特流传输 |
| OSI中的层 | 功能 | TCP/IP协议簇 |
|---|---|---|
| 应用层 | 文件传输,电子邮件,文件服务,虚拟终端 | TFTP,HTTP,SNMP,FTP,SMTP,DNS,RIP,Telnet |
| 表示层 | 数据格式化,代码转换,数据加密 | 没有协议 |
| 会话层 | 解除或建立与别的接点的联系 | 没有协议 |
| 传输层 | 提供端对端的接口 | TCP,UDP |
| 网络层 | 为数据包选择路由 | IP,ICMP,OSPF,BGP,IGMP,ARP,RARP |
| 数据链路层 | 传输有地址的帧以及错误检测功能 | SLIP,CSLIP,PPP,MTU,ARP,RARP |
| 物理层 | 以二进制数据形式在物理媒体上传输数据 | IS02110,IEEE802,IEEE802.2 |
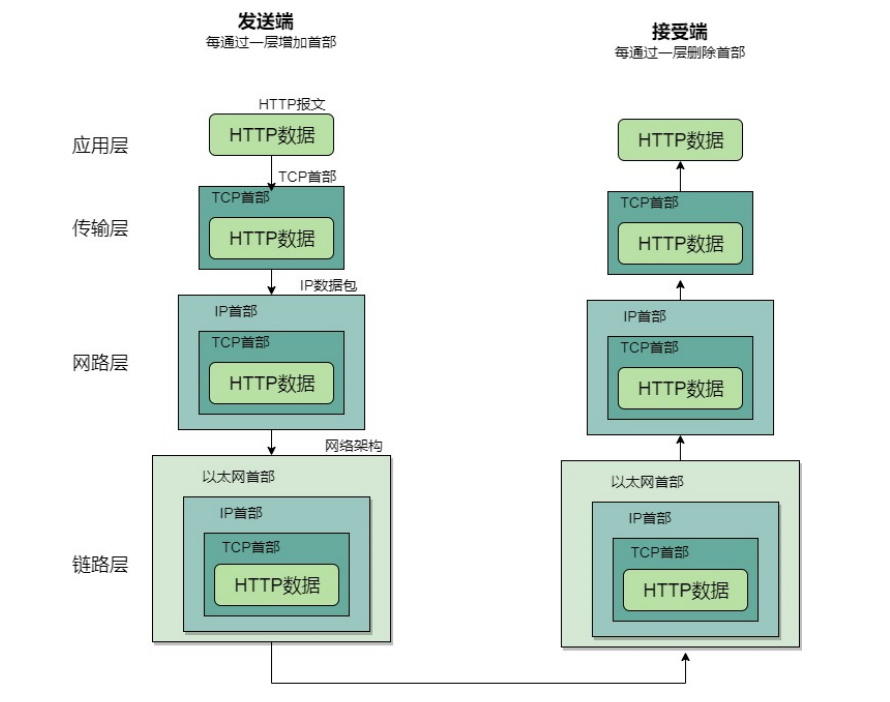
在数据的实际传输中,发送方将数据送到自己的应用层,加上该层的控制信息后传给表示层;表示层如法炮制,再将数据加上自己的标识传给会话层;以此类推,每一层都在收到的数据上加上本层的控制信息并传给下一层;最后到达物理层时,数据通过实际的物理媒体传到接收方。接收端则执行与发送端相反的操作,由下往上,将逐层标识去掉,重新还原成最初的数据。由此可见,数据通讯双方在对等层必须采用相同的协议,定义同一种数据标识格式,这样才可能保证数据的正确传输。
1、物理层Physical(以二进制数据形式在物理媒体上传输数据)
数据实际传输;
科学家要解决的第一个问题是,两个硬件之间怎么通信。具体就是一台发些比特流,然后另一台能收到。于是,科学家发明了物理层:主要定义物理设备标准,如网线的接口类型、光纤的接口类型、各种传输介质的传输速率等。它的主要作用是传输比特流(就是由1、0转化为电流强弱来进行传输,到达目的地后在转化为1、0,也就是我们常说的数模转换与模数转换)。这一层的数据叫做比特。
2、数据链路层Data Link(传输有地址的帧以及错误检测功能 )
MAC地址编址;MAC地址寻址;差错校验
现在通过电线我能发数据流了,但是,我还希望通过无线电波,通过其它介质来传输。然后我还要保证传输过去的比特流是正确的,要有纠错功能。
于是,发明了数据链路层:定义了如何让格式化数据以进行传输,以及如何让控制对物理介质的访问。这一层通常还提供错误检测和纠正,以确保数据的可靠传输。
3:网络层Network (为数据包选择路由)
IP地址编制;路由选择(静态路由和动态路由)
如果我有多台计算机,怎么找到我要发的那台?或者,A要给F发信息,中间要经过B,C,D,E,但是中间还有好多节点如K.J.Z.Y。我怎么选择最佳路径?这就是路由要做的事。
于是,发明了网络层。即路由器,交换机那些具有寻址功能的设备所实现的功能。这一层定义的是IP地址,通过IP地址寻址。所以产生了IP协议。
4: 传输层Transport (提供端对端的接口协议,TCP/OCP等)
对报文进行分组(发送时)、组装(接收时);提供传输协议选择、TCP(传输控制协议)或者UDP(用户数据报协议);端口封装;差错校验
现在我能发正确的发比特流数据到另一台计算机了,但是当我发大量数据时候,可能需要好长时间,例如一个视频格式的,网络会中断好多次(事实上,即使有了物理层和数据链路层,网络还是经常中断,只是中断的时间是毫秒级别的)。
那么,我还须要保证传输大量文件时的准确性。于是,我要对发出去的数据进行封装。就像发快递一样,一个个地发。
例如TCP,是用于发大量数据的,我发了1万个包出去,另一台电脑就要告诉我是否接受到了1万个包,如果缺了3个包,就告诉我是第1001,234,8888个包丢了,那我再发一次。这样,就能保证对方把这个视频完整接收了。
例如UDP,是用于发送少量数据的。我发20个包出去,一般不会丢包,所以,我不管你收到多少个。在多人互动游戏,也经常用UDP协议,因为一般都是简单的信息,而且有广播的需求。如果用TCP,效率就很低,因为它会不停地告诉主机我收到了20个包,或者我收到了18个包,再发我两个!如果同时有1万台计算机都这样做,那么用TCP反而会降低效率,还不如用UDP,主机发出去就算了,丢几个包你就卡一下,算了,下次再发包你再更新。
5:会话层Session(解除与建立与别的接口的联系)
确定数据是否要经过网络传输
现在我们已经保证给正确的计算机,发送正确的封装过后的信息了。但是用户级别的体验好不好?难道我每次都要调用TCP去打包,然后调用IP协议去找路由,自己去发?当然不行,所以我们要建立一个自动收发包,自动寻址的功能。
于是,发明了会话层。会话层的作用就是建立和管理应用程序之间的通信。
6:表示层Presentation(数据格式化,代码转换,数据加密)
现在我能保证应用程序自动收发包和寻址了。但是我要用Linux给window发包,两个系统语法不一致,就像安装包一样,exe是不能在linux下用的,shell在window下也是不能直接运行的。于是需要表示层(presentation),帮我们解决不同系统之间的通信语法问题。
7:应用层Application(文件传输,电子邮件,文件服务,虚拟终端)
传输的数据根据应用层的协议进行服务
应用层由来:用户使用的都是应用程序,均工作于应用层,互联网是开发的,大家都可以开发自己的应用程序,数据多种多样,必须规定好数据的组织形式 。
应用层功能:规定应用程序的数据格式。
例:TCP协议可以为各种各样的程序传递数据,比如Email、WWW、FTP等等。那么,必须有不同协议规定电子邮件、网页、FTP数据的格式,这些应用程序协议就构成了”应用层”。
2、TCP/IP四层模型
| 应用层 | Hytera自有传输协议 |
|---|---|
| 传输层 | TCP UDP |
| 网络层 | IP ICMP |
| 物理链路层 | 根据需求选择不同物理链路 |
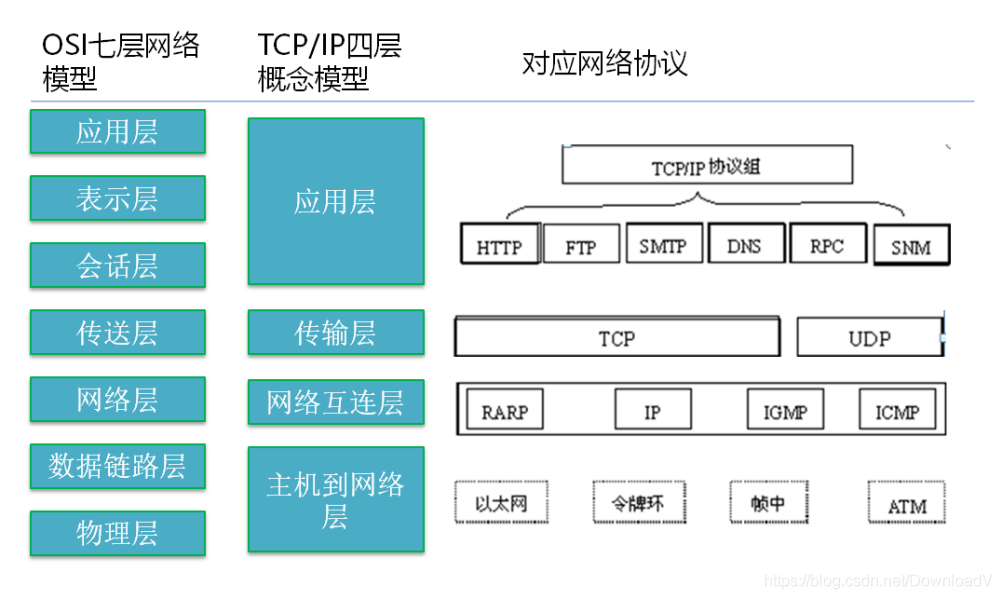
3、OSI七层和TCP/IP四层的关系
-
OSI引入了服务、接口、协议、分层的概念,TCP/IP借鉴了OSI的这些概念建立TCP/IP模型。
-
OSI先有模型,后有协议,先有标准,后进行实践;而TCP/IP则相反,先有协议和应用再提出了模型,且是参照的OSI模型。
-
OSI是一种理论下的模型,而TCP/IP已被广泛使用,成为网络互联事实上的标准。
-
TCP:transmission control protocol 传输控制协议
-
UDP:user data protocol 用户数据报协议
-
1、对应关系
TCP/IP五层协议和OSI的七层协议对应关系如下。
| OSI参考模型 | ТСР/IР 五层模型 | 协议 |
|---|---|---|
| 应用层 | ||
| 表示层 | 应用层 | 应用层(HTTP Telnet FTP TFTP DNS SMTP) |
| 会话层 | ||
| 传输层 | 传输层 | 四层交换机、四层的路由器(TCP UDP) |
| 网络层 | 网络层 | 路由、三层交换机(IP ICMP RIP IGMP) |
| 数据链路层 | 数据链路层 | 网桥、以太网交换机、网卡(ARP RARP IEEE802.3 PPP) |
| 物理层 | 物理层 | 中继器、集线器、双绞线(FE自协商Manchester MLT—3) |
2、相关协议
| OSI七层模型 | 缩写 | 相关协议 | 缩写 | 相关协议 |
|---|---|---|---|---|
| 应用层 | HTTP | 超文本传输协议 | FTP | 文件传输协议 |
| SMTP | 简单邮件传输协议 | TELNET | TCP/IP终端仿真协议 | |
| POP3 | 邮局协议第三版 | Finger | 用户信息协议 | |
| NNTP | 网络新闻传输协议 | IMAP4 | 因特网信息访问协议第四版 | |
| LPR | UNIX 远程打印协议 | Rwho | UNIX远程Who协议 | |
| Rexec | UNIX远程执行协议 | Login | UNIX远程登陆协议 | |
| RSH | UNTX 远程Shell协议 | NTF | HP网络文件传输协议 | |
| RDA | HP远程数据库访问协议 | VT | 虚拟终端仿真协议 | |
| RFA | HP远程文件访问协议 | RPC | Remote Process Comm. | |
| S-HTTP | 安全超文本传输协议 | GDP | 网关发现协议 | |
| x-Window | CMOT | 基于TCP/IP的CMIP协议 | SOCKS | 安全套接字协议 |
| FANP | 流属性通知协议 | SLP | 服务定位协议 | |
| MSN | 微软网络服务 | Radius | 远程用户拨号认证服务协议 | |
| DNS | 域名系统 | NFS | 网络文件系统协议 | |
| NIS | SUN网络信息系统协议 | R-STAT | SUN远程状态协议 | |
| NSM | SUN网络状态监测协议 | PMAP | SUN端口映射协议 | |
| Mount | LPR | UNTX远程打印协议 | ||
| 常用UDP协议的应用层服务 | BOOTP | 引导协议 | DHCP | 动态主机配套协议 |
| NTP | 网络时间协议 | TFTP | 简单文件传输协议 | |
| SNMP | 简单网络管理协议 | |||
| 表示层 | DECnet | NSP | LPP | 轻量级表示协议 |
| NBSSN | NetBIOS会话服务协议 | XDP | 外部数据表示协议 | |
| IPX | 互联网分组交换协议 | |||
| 会话层 | SSL | 安全套接字层协议 | TLS | 传输层安全协议 |
| DAP | 目录访问协议 | LDAP | 轻量级目录访问协议 | |
| RPC | 远程过程调用协议 | VINES | NETRPC | |
| 传输层 | XOT | 基于top之上的X协议 | Van Jacobson | 压缩TCP协议 |
| ISO-DE | ISO开发环境--NetBISO | TALI | 传输适配层接口协议 | |
| UDP | 用户数据报协议 | RUDP | 可靠的用户数据报协议 | |
| Mobile | IP移动IP协议 | |||
| 网络层 | IP/IPv6 | 互联网协议/互联网协议第六版 | ICMPv6 | 互联网控制信息协议第六版 |
| TCMP | 互联网控制信息协议 | IGMP | 互联网组管理协议 | |
| SLIP | 串行线路IP协议 | |||
| 安全协议 | AH | 认证头协议 | ESP | 安装封装有效载荷协议 |
| 路由协议 | EGP | 外部网关协议 | OSPF | 开放最短路径优先协议 |
| IGRP | 内部网关路由协议 | NHRP | 下一跳解析协议 | |
| TE-IRGP | 增强内部网关路由选择协议 | RIPng for IPv6 | IPv6路由信息协议 | |
| GGP | 网关到网关协议 | VRRP | 虚拟路由器冗余协议 | |
| PGM | 实际通用组播协议 | RSVP | 资源预留协议 | |
| PIM-DM | 密集模式独立组播协议 | DVMRP | 距离矢量组播路由协议 | |
| RIP2 | 路由信息协议第二版 | PIM-SM | 稀疏模式独立组播协议 | |
| MOSP | 组播开放最短路径优先协议 | |||
| 数据链路层 | MPLS | 多协议标签交换协议 | XTP | 压缩传输协议 |
| DCAP | 数据转换客户访问协议 | SLE | 串行连接封装协议 | |
| IPinIP | IP套IP封装协议 | |||
| 隧道协议 | PPTP | 点对点隧道协议 | L2F | 第二层转发协议 |
| L2TP | 第二层隧道协议 | ATMP | 接入隧道管理协议 | |
| Cisco协议 | CDP | 思科发现协议 | CCMP | 思科组管理协议 |
| 地址解析协议 | ARP | 地址解析协议 | RAR | 逆向地址解析协议 |
| 物理层 | IEEE802.2 | Ethernet v.2 | ||
| Internetwork |
4、TCP/IP数据包说明
IP层传输单位是IP分组,属于点到点的传输;TCP层传输单位是TCP段,属于端到端的传输
5、TCP的三次握手、四次挥手
Tcp报文
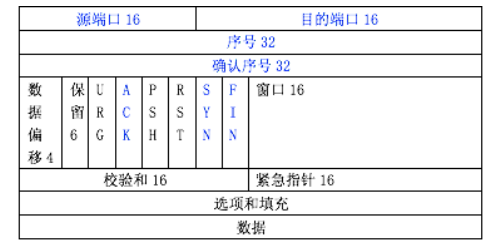
序号:表示发送的数据字节流,确保TCP传输有序,对每个字节编号
确认序号:发送方期待接收的下一序列号,接收成功后的数据字节序列号加 1。只有ACK=1时才有效。
ACK:确认序号的标志,ACK=1表示确认号有效,ACK=0表示报文不含确认序号信息
SYN:连接请求序号标志,用于建立连接,SYN=1表示请求连接
FIN:结束标志,用于释放连接,为1表示关闭本方数据流
1、三次握手
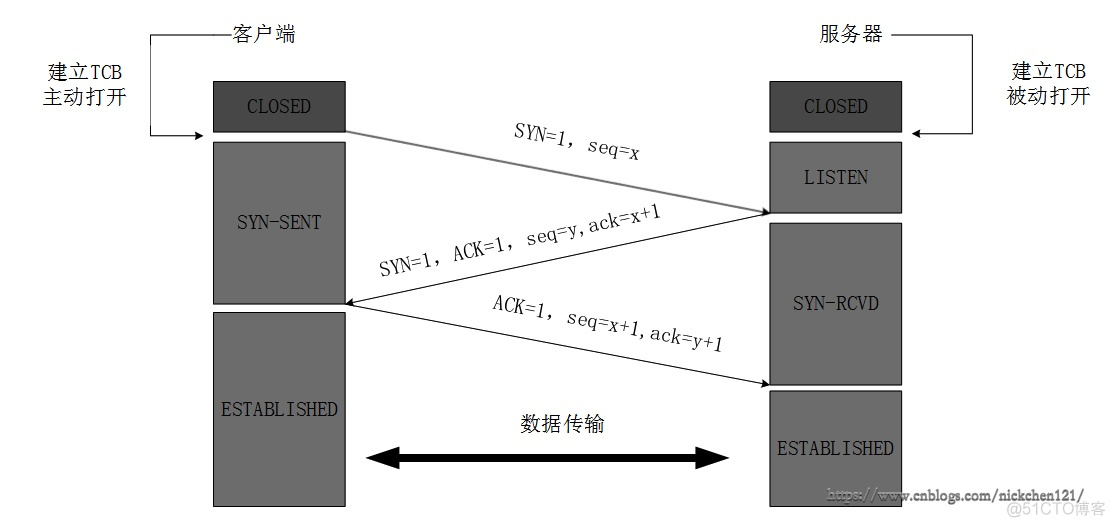
第一次:客户端发送初始序号x和syn=1请求标志
第二次:服务器发送请求标志syn,发送确认标志ACK,发送自己的序号seq=y,发送客户端的确认序号ack=x+1
第三次:客户端发送ACK确认号,发送自己的序号seq=x+1,发送对方的确认号ack=y+1
2、四次挥手
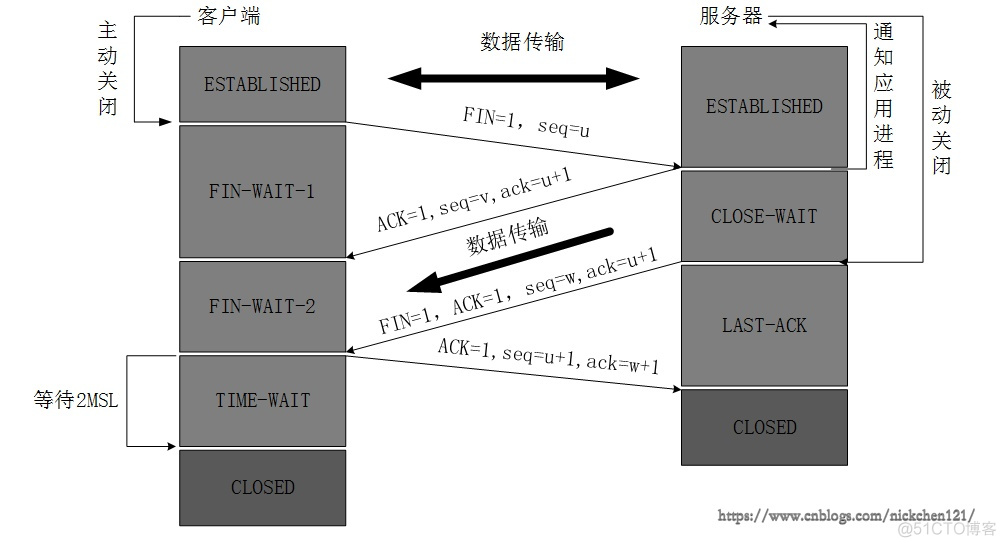
第一次:客户端请求断开FIN,seq=u
第二次:服务器确认客户端的断开请求ACK,ack=u+1,seq=v
第三次:服务器请求断开FIN,seq=w,ACK,ack=u+1
第四次:客户端确认服务器的断开ACK,ack=w+1,seq=u+1
6、状态转换
7、TCP队列
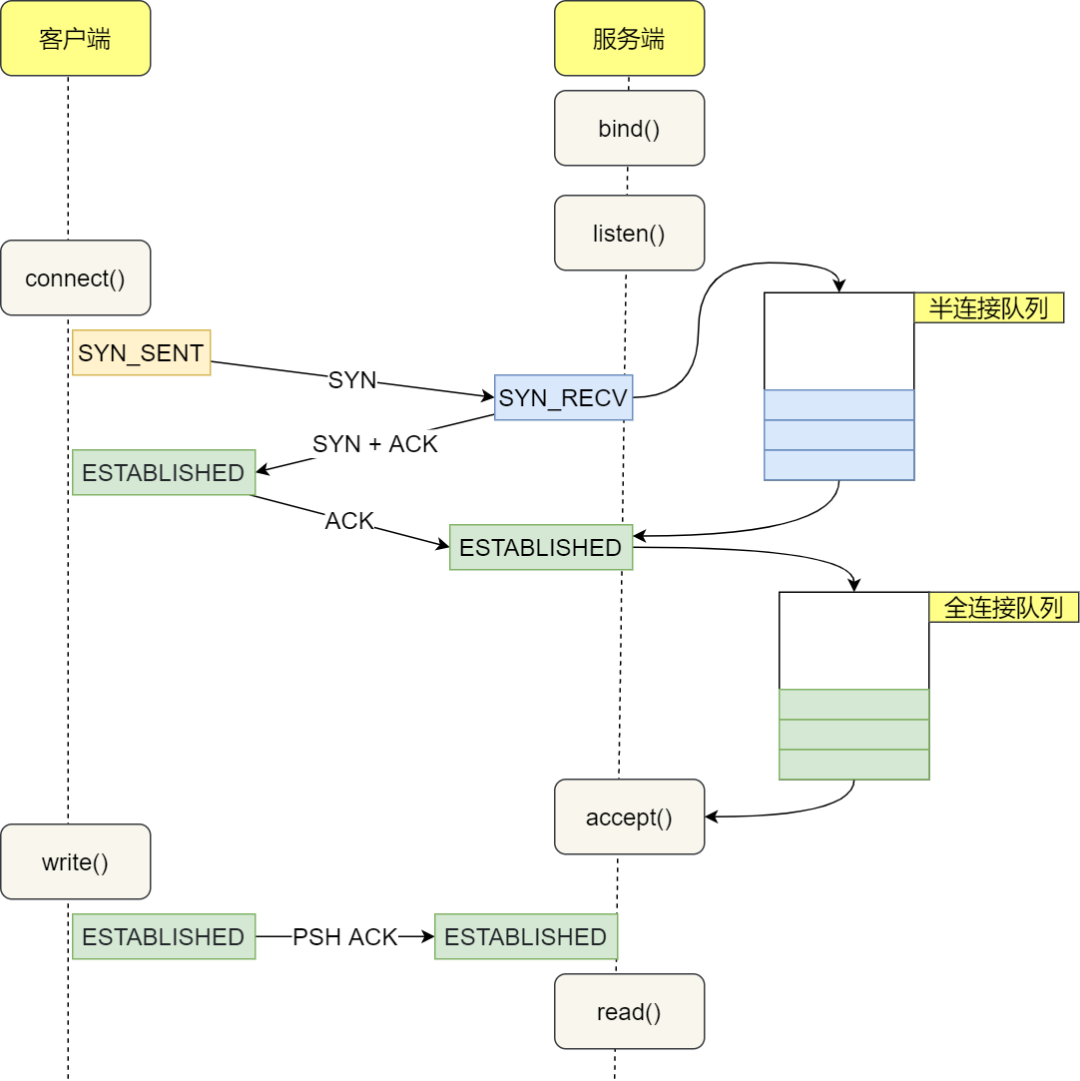
什么是 TCP 半连接队列和全连接队列?
在 TCP 三次握手的时候,Linux 内核会维护两个队列,分别是:
- 半连接队列,也称 SYN 队列;
- 全连接队列,也称 accepet 队列;
服务端收到客户端发起的 SYN 请求后,内核会把该连接存储到半连接队列,并向客户端响应 SYN+ACK,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其添加到 accept 队列,等待进程调用 accept 函数时把连接取出来。
。
 半连接
半连接
队列与全连接队列
不管是半连接队列还是全连接队列,都有最大长度限制,超过限制时,内核会直接丢弃,或返回 RST 包。
实战 - TCP 全连接队列溢出
如何知道应用程序的 TCP 全连接队列大小?
在服务端可以使用 ss 命令,来查看 TCP 全连接队列的情况:
但需要注意的是 ss 命令获取的 Recv-Q/Send-Q 在「LISTEN 状态」和「非 LISTEN 状态」所表达的含义是不同的。
在「LISTEN 状态」时,Recv-Q/Send-Q 表示的含义如下:
# ss -lnt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 511 *:80 *:*
# -l 显示正在监听(listening)的socket
# -n 不解析服务名称
# -t 只显示 tcp socket
- Recv-Q:当前全连接队列的大小,也就是当前已完成三次握手并等待服务端
accept()的 TCP 连接个数; - Send-Q:当前全连接最大队列长度,上面的输出结果说明监听 80 端口的 TCP 服务进程,最大全连接长度为 511;
在「非 LISTEN 状态」时,Recv-Q/Send-Q 表示的含义如下:
# ss -nt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 192.168.0.173:60011 100.100.30.26:80
# -n 不解析服务名称
# -t 只显示 tcp socket
- Recv-Q:已收到但未被应用进程读取的字节数;
- Send-Q:已发送但未收到确认的字节数
模拟 TCP 全连接队列溢出
实验环境:
- 客户端和服务端都是 CentOs 6.5 ,Linux 内核版本 2.6.32
- 服务端 IP 192.168.0.172,客户端 IP 192.168.0.170
- 服务端是 Nginx 服务,端口为 80
这里先介绍下 wrk 工具,它是一款简单的 HTTP 压测工具,它能够在单机多核 CPU 的条件下,使用系统自带的高性能 I/O 机制,通过多线程和事件模式,对目标机器产生大量的负载。
本次模拟实验就使用 wrk 工具来压力测试服务端,发起大量的请求,一起看看服务端 TCP 全连接队列满了会发生什么?有什么观察指标?
# 前置环境安装
yum install -y git make gcc unzip
git clone https://mirror.ghproxy.com/https://github.com/wg/wrk.git
cd wrk
make
客户端执行 wrk 命令对服务端发起压力测试,并发 3 万个连接:
# ./wrk -t 6 -c 30000 -d 60s http://192.168.0.172:80
Running 1m test @ http://192.168.0.172:80
6 threads and 30000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 389.03ms 279.65ms 1.96s 83.79%
Req/Sec 655.82 419.20 3.08k 75.40%
206778 requests in 1.01m, 168.21MB read
Socket errors: connect 0, read 1454103, write 0, timeout 6243
Requests/sec: 3428.20
Transfer/sec: 2.79MB
在服务端可以使用 ss 命令,来查看当前 TCP 全连接队列的情况:
# ss -lnt | grep 80
LISTEN 24 511 *:80 *:*
# ss -lnt | grep 80
LISTEN 109 511 *:80 *:*
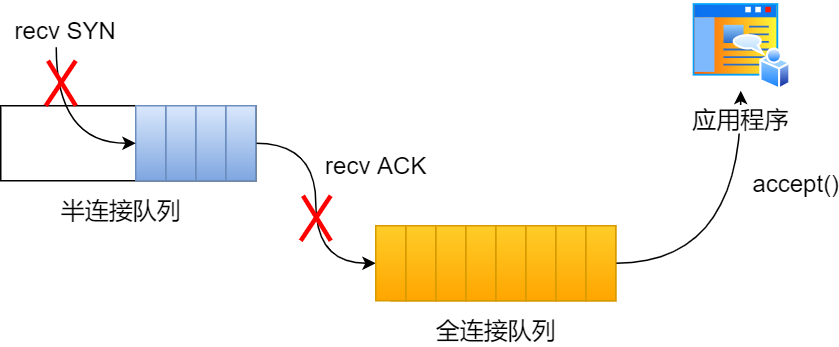
其间共执行了两次 ss 命令,从上面的输出结果,可以发现当前 TCP 全连接队列上升到了 129 大小,超过了最大 TCP 全连接队列。
当超过了 TCP 最大全连接队列,服务端则会丢掉后续进来的 TCP 连接,丢掉的 TCP 连接的个数会被统计起来,我们可以使用 netstat -s 命令来查看:
# 查看 TCP 全连接队列溢出情况
# date;netstat -s | grep overflowed
Thu Mar 2 11:34:36 CST 2023
6270 times the listen queue of a socket overflowed
# date;netstat -s | grep overflowed
Thu Mar 2 11:34:42 CST 2023
7485 times the listen queue of a socket overflowed
上面看到的 7485 times ,表示全连接队列溢出的次数,注意这个是累计值。可以隔几秒钟执行下,如果这个数字一直在增加的话肯定全连接队列偶尔满了。
从上面的模拟结果,可以得知,当服务端并发处理大量请求时,如果 TCP 全连接队列过小,就容易溢出。发生 TCP 全连接队溢出的时候,后续的请求就会被丢弃,这样就会出现服务端请求数量上不去的现象。
 全连接队列溢出
全连接队列溢出
全连接队列满了,就只会丢弃连接吗?
实际上,丢弃连接只是 Linux 的默认行为,我们还可以选择向客户端发送 RST 复位报文,告诉客户端连接已经建立失败。
# cat /proc/sys/net/ipv4/tcp_abort_on_overflow
0
tcp_abort_on_overflow 共有两个值分别是 0 和 1,其分别表示:
- 0 :表示如果全连接队列满了,那么 server 扔掉 client 发过来的 ack ;
- 1 :表示如果全连接队列满了,那么 server 发送一个
reset包给 client,表示废掉这个握手过程和这个连接;
如果要想知道客户端连接不上服务端,是不是服务端 TCP 全连接队列满的原因,那么可以把 tcp_abort_on_overflow 设置为 1,这时如果在客户端异常中可以看到很多 connection reset by peer 的错误,那么就可以证明是由于服务端 TCP 全连接队列溢出的问题。
通常情况下,应当把 tcp_abort_on_overflow 设置为 0,因为这样更有利于应对突发流量。
举个例子,当 TCP 全连接队列满导致服务器丢掉了 ACK,与此同时,客户端的连接状态却是 ESTABLISHED,进程就在建立好的连接上发送请求。只要服务器没有为请求回复 ACK,请求就会被多次重发。如果服务器上的进程只是短暂的繁忙造成 accept 队列满,那么当 TCP 全连接队列有空位时,再次接收到的请求报文由于含有 ACK,仍然会触发服务器端成功建立连接。
所以,tcp_abort_on_overflow 设为 0 可以提高连接建立的成功率,只有你非常肯定 TCP 全连接队列会长期溢出时,才能设置为 1 以尽快通知客户端。
如何增大 TCP 全连接队列呢?
是的,当发现 TCP 全连接队列发生溢出的时候,我们就需要增大该队列的大小,以便可以应对客户端大量的请求。
TCP 全连接队列足最大值取决于 somaxconn 和 backlog 之间的最小值,也就是 min(somaxconn, backlog)。从下面的 Linux 内核代码可以得知:
前面模拟测试中,我的测试环境:
- somaxconn 是默认值 128;
- Nginx 的 backlog 是默认值 511
所以测试环境的 TCP 全连接队列最大值为 min(128, 511),也就是 128,可以执行 ss 命令查看:
# ss -lnt | grep 80
LISTEN 0 511 *:80 *:*
现在我们重新压测,把 TCP 全连接队列搞大,把 somaxconn 设置成 5000:
# echo 5000 > /proc/sys/net/core/somaxconn
echo 32768 > /proc/sys/net/core/somaxconn
接着把 Nginx 的 backlog 也同样设置成 5000:
server {
listen 80 default backlog=5000;
server_name localhost;
最后要重启 Nginx 服务,因为只有重新调用 listen() 函数, TCP 全连接队列才会重新初始化。
重启完后 Nginx 服务后,服务端执行 ss 命令,查看 TCP 全连接队列大小:
# ss -lnt | grep 80
LISTEN 0 5000 *:80 *:*
从执行结果,可以发现 TCP 全连接最大值为 5000。
增大 TCP 全连接队列后,继续压测
客户端同样以 3 万个连接并发发送请求给服务端,服务端执行 ss 命令,查看 TCP 全连接队列使用情况:
# ss -lnt | grep 80
LISTEN 176 5000 *:80 *:*
从上面的执行结果,可以发现全连接队列使用增长的很快,但是一直都没有超过最大值,所以就不会溢出,那么 netstat -s 就不会有 TCP 全连接队列溢出个数的显示:
# netstat -s | grep overflowed
说明 TCP 全连接队列最大值从 128 增大到 5000 后,服务端抗住了 3 万连接并发请求,也没有发生全连接队列溢出的现象了。
如果持续不断地有连接因为 TCP 全连接队列溢出被丢弃,就应该调大 backlog 以及 somaxconn 参数。
实战 - TCP 半连接队列溢出
如何查看 TCP 半连接队列长度?
很遗憾,TCP 半连接队列长度的长度,没有像全连接队列那样可以用 ss 命令查看。
但是我们可以抓住 TCP 半连接的特点,就是服务端处于 SYN_RECV 状态的 TCP 连接,就是在 TCP 半连接队列。
于是,我们可以使用如下命令计算当前 TCP 半连接队列长度:
如何查看 TCP 半连接队列长度?
很遗憾,TCP 半连接队列长度的长度,没有像全连接队列那样可以用 ss 命令查看。
但是我们可以抓住 TCP 半连接的特点,就是服务端处于 SYN_RECV 状态的 TCP 连接,就是在 TCP 半连接队列。
于是,我们可以使用如下命令计算当前 TCP 半连接队列长度:

如何模拟 TCP 半连接队列溢出场景?
模拟 TCP 半连接溢出场景不难,实际上就是对服务端一直发送 TCP SYN 包,但是不回第三次握手 ACK,这样就会使得服务端有大量的处于 SYN_RECV 状态的 TCP 连接。
这其实也就是所谓的 SYN 洪泛、SYN 攻击、DDos 攻击。
测试环境
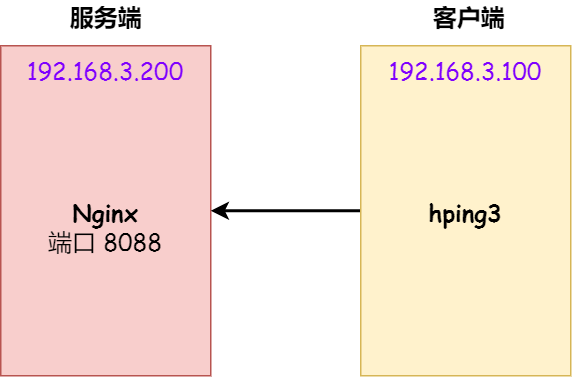
实验环境:
- 客户端和服务端都是 CentOs 6.5 ,Linux 内核版本 2.6.32
- 服务端 IP 192.168.3.200,客户端 IP 192.168.3.100
- 服务端是 Nginx 服务,端口为 8088
注意:本次模拟实验是没有开启 tcp_syncookies,关于 tcp_syncookies 的作用,后续会说明。
本次实验使用 hping3 工具模拟 SYN 攻击:

当服务端受到 SYN 攻击后,连接服务端 ssh 就会断开了,无法再连上。只能在服务端主机上执行查看当前 TCP 半连接队列大小:

同时,还可以通过 netstat -s 观察半连接队列溢出的情况:
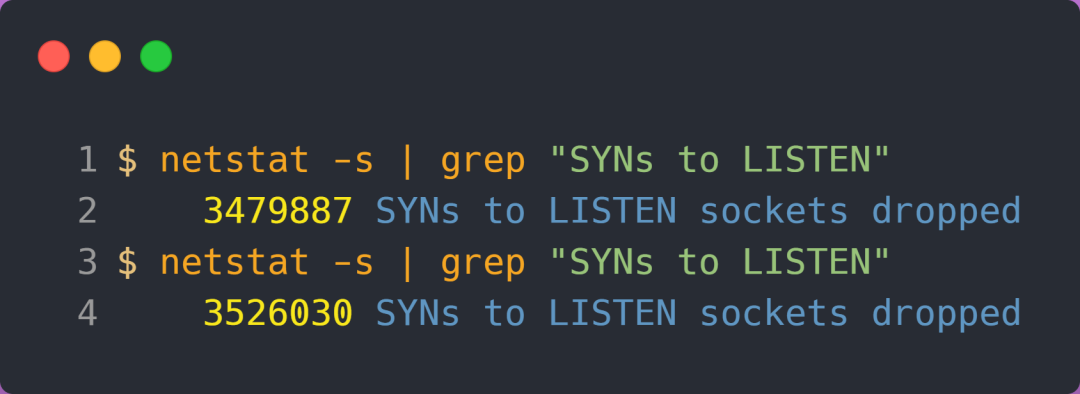
上面输出的数值是累计值,表示共有多少个 TCP 连接因为半连接队列溢出而被丢弃。隔几秒执行几次,如果有上升的趋势,说明当前存在半连接队列溢出的现象。
大部分人都说 tcp_max_syn_backlog 是指定半连接队列的大小,是真的吗?
很遗憾,半连接队列的大小并不单单只跟 tcp_max_syn_backlog 有关系。
上面模拟 SYN 攻击场景时,服务端的 tcp_max_syn_backlog 的默认值如下:
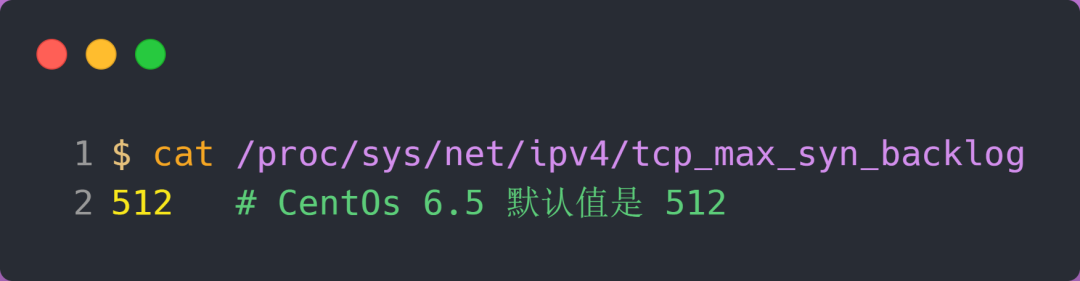
但是在测试的时候发现,服务端最多只有 256 个半连接队列,而不是 512,所以半连接队列的最大长度不一定由 tcp_max_syn_backlog 值决定的。
接下来,走进 Linux 内核的源码,来分析 TCP 半连接队列的最大值是如何决定的。
TCP 第一次握手(收到 SYN 包)的 Linux 内核代码如下,其中缩减了大量的代码,只需要重点关注 TCP 半连接队列溢出的处理逻辑:
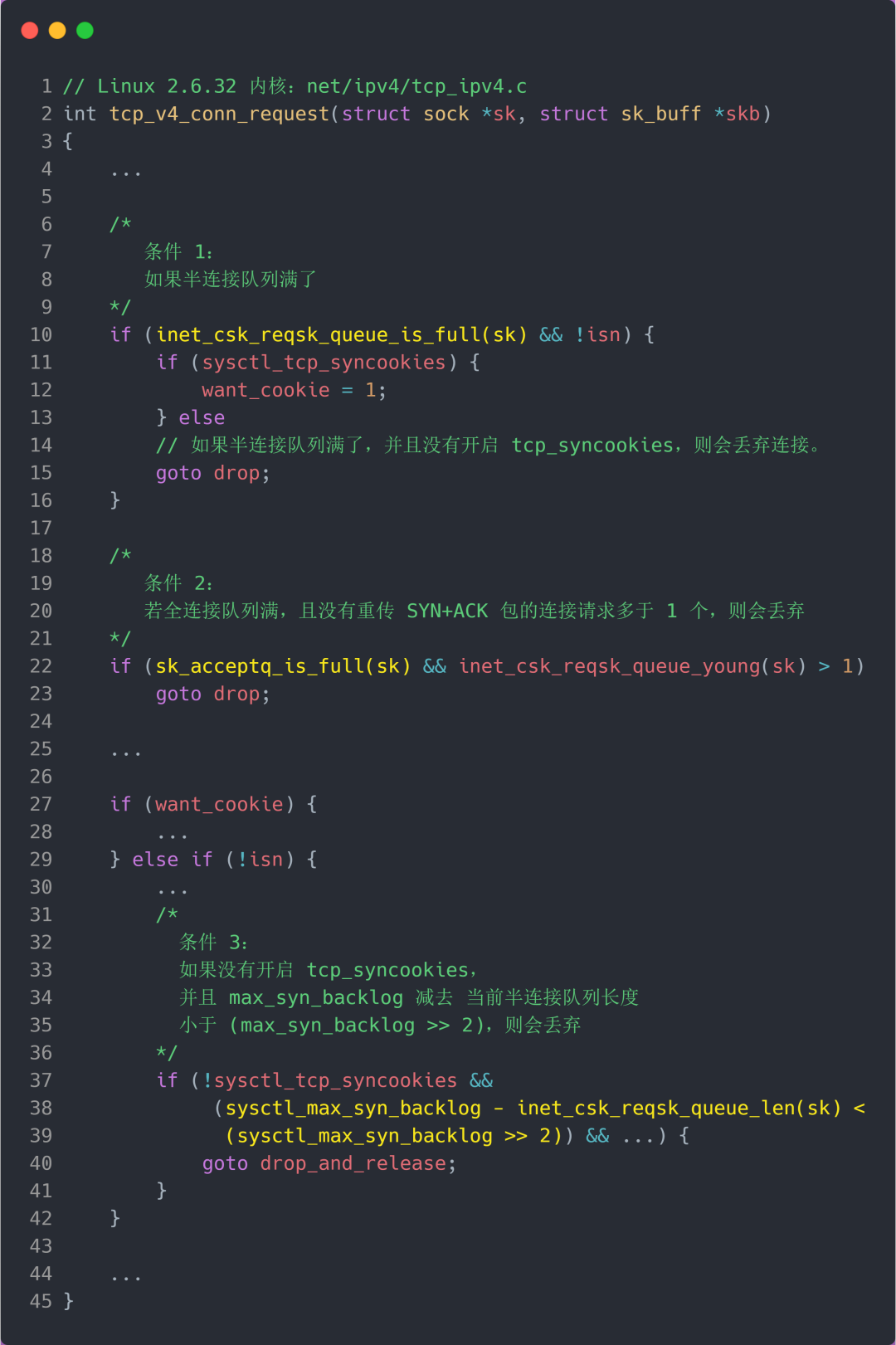
从源码中,我可以得出共有三个条件因队列长度的关系而被丢弃的:
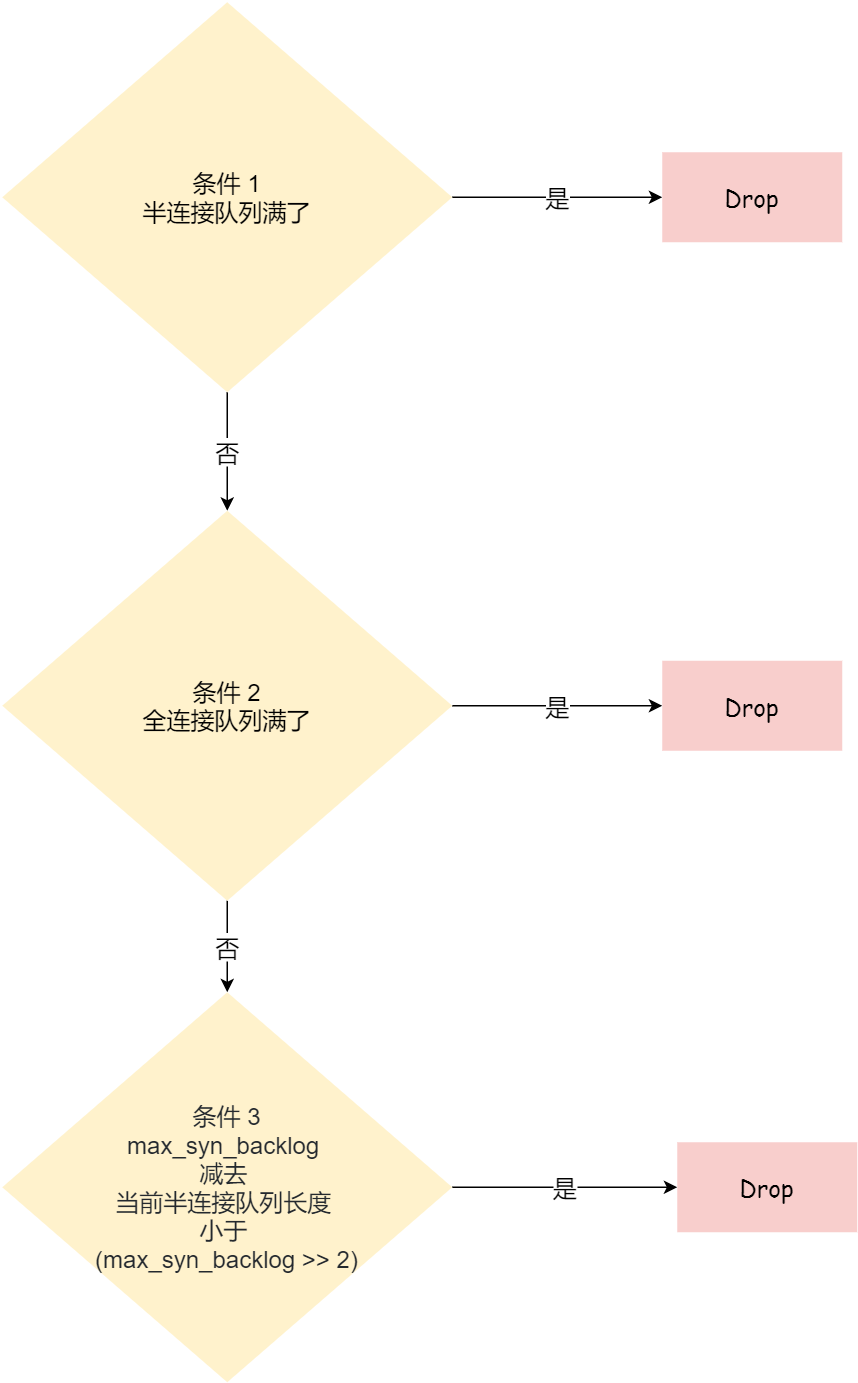
- 如果半连接队列满了,并且没有开启 tcp_syncookies,则会丢弃;
- 若全连接队列满了,且没有重传 SYN+ACK 包的连接请求多于 1 个,则会丢弃;
- 如果没有开启 tcp_syncookies,并且 max_syn_backlog 减去 当前半连接队列长度小于 (max_syn_backlog >> 2),则会丢弃;
关于 tcp_syncookies 的设置,后面在详细说明,可以先给大家说一下,开启 tcp_syncookies 是缓解 SYN 攻击其中一个手段。
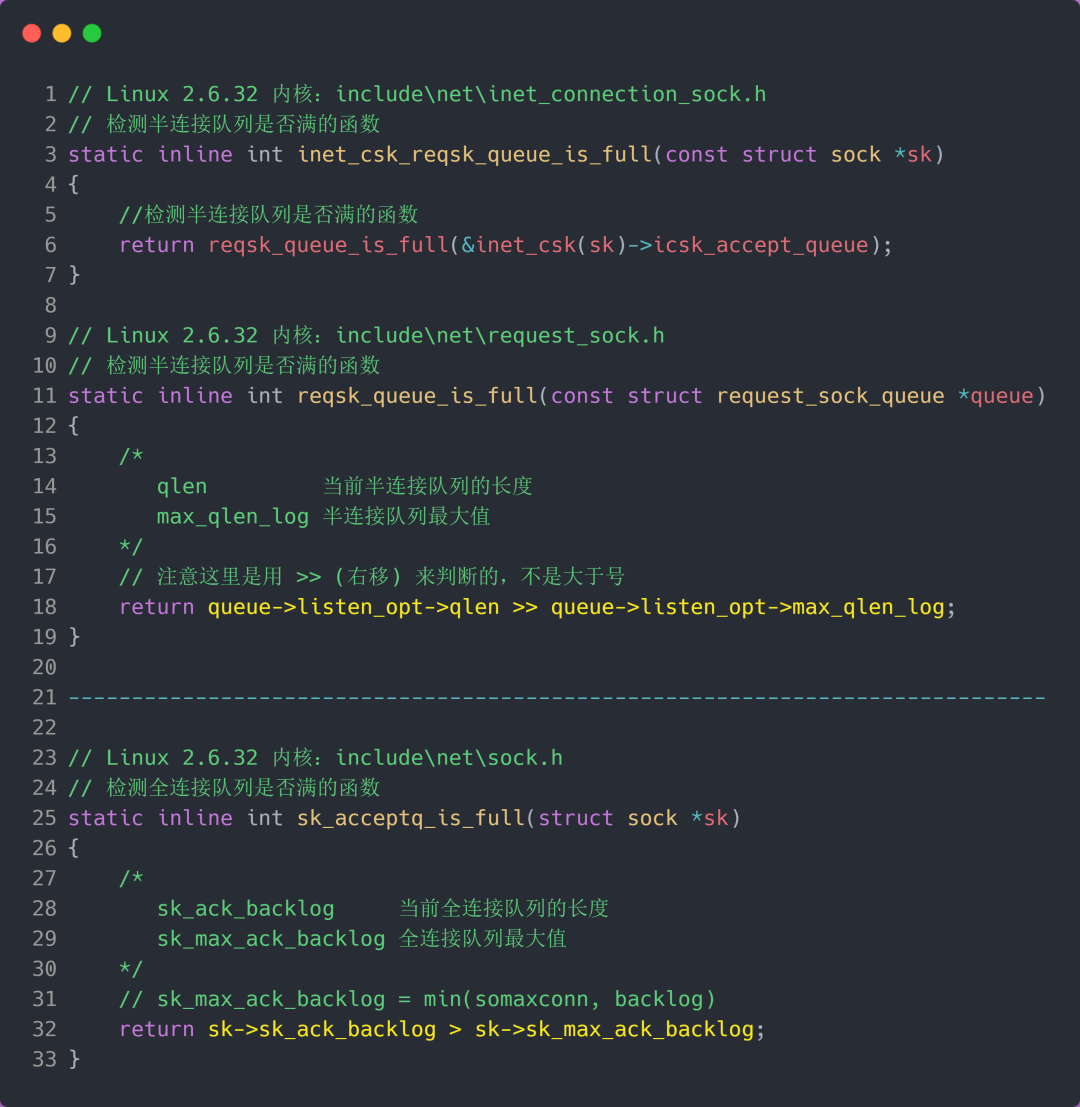
接下来,我们继续跟一下检测半连接队列是否满的函数 inet_csk_reqsk_queue_is_full 和 检测全连接队列是否满的函数 sk_acceptq_is_full :
从上面源码,可以得知:
- 全连接队列的最大值是
sk_max_ack_backlog变量,sk_max_ack_backlog 实际上是在 listen() 源码里指定的,也就是 min(somaxconn, backlog); - 半连接队列的最大值是
max_qlen_log变量,max_qlen_log 是在哪指定的呢?现在暂时还不知道,我们继续跟进;
我们继续跟进代码,看一下是哪里初始化了半连接队列的最大值 max_qlen_log:
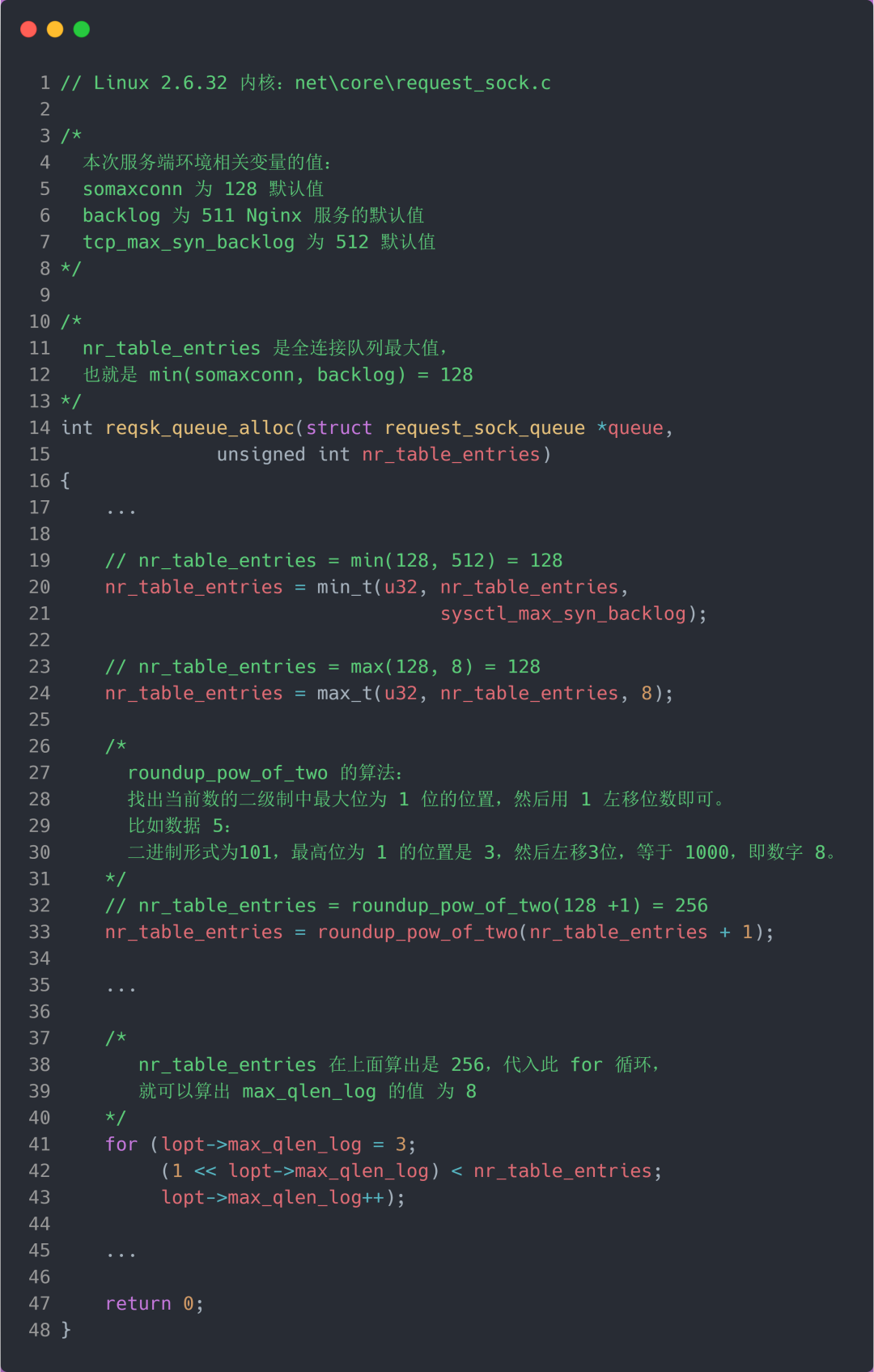
从上面的代码中,我们可以算出 max_qlen_log 是 8,于是代入到 检测半连接队列是否满的函数 reqsk_queue_is_full :
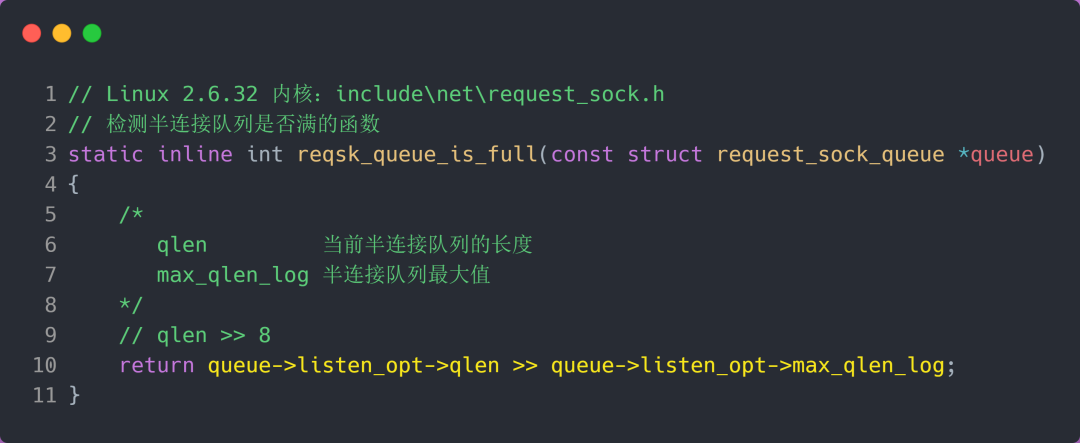
也就是 qlen >> 8 什么时候为 1 就代表半连接队列满了。这计算这不难,很明显是当 qlen 为 256 时,256 >> 8 = 1。
至此,总算知道为什么上面模拟测试 SYN 攻击的时候,服务端处于 SYN_RECV 连接最大只有 256 个。
可见,半连接队列最大值不是单单由 max_syn_backlog 决定,还跟 somaxconn 和 backlog 有关系。
在 Linux 2.6.32 内核版本,它们之间的关系,总体可以概况为:
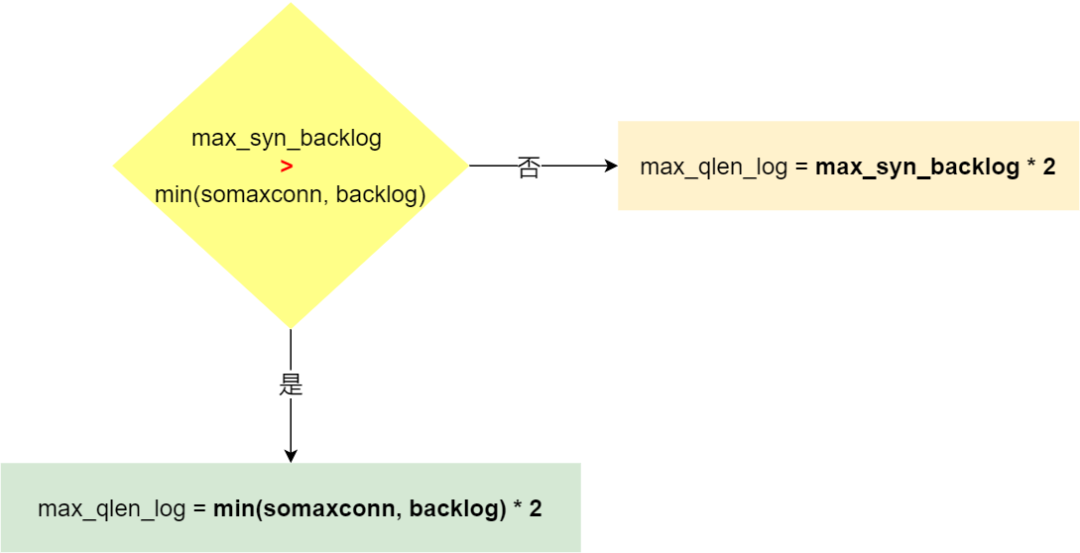
- 当 max_syn_backlog > min(somaxconn, backlog) 时, 半连接队列最大值 max_qlen_log = min(somaxconn, backlog) * 2;
- 当 max_syn_backlog < min(somaxconn, backlog) 时, 半连接队列最大值 max_qlen_log = max_syn_backlog * 2;
半连接队列最大值 max_qlen_log 就表示服务端处于 SYN_REVC 状态的最大个数吗?
依然很遗憾,并不是。
max_qlen_log 是理论半连接队列最大值,并不一定代表服务端处于 SYN_REVC 状态的最大个数。
在前面我们在分析 TCP 第一次握手(收到 SYN 包)时会被丢弃的三种条件:
- 如果半连接队列满了,并且没有开启 tcp_syncookies,则会丢弃;
- 若全连接队列满了,且没有重传 SYN+ACK 包的连接请求多于 1 个,则会丢弃;
- 如果没有开启 tcp_syncookies,并且 max_syn_backlog 减去 当前半连接队列长度小于 (max_syn_backlog >> 2),则会丢弃;
假设条件 1 当前半连接队列的长度 「没有超过」理论的半连接队列最大值 max_qlen_log,那么如果条件 3 成立,则依然会丢弃 SYN 包,也就会使得服务端处于 SYN_REVC 状态的最大个数不会是理论值 max_qlen_log。
似乎很难理解,我们继续接着做实验,实验见真知。
服务端环境如下:

配置完后,服务端要重启 Nginx,因为全连接队列最大和半连接队列最大值是在 listen() 函数初始化。
根据前面的源码分析,我们可以计算出半连接队列 max_qlen_log 的最大值为 256:

客户端执行 hping3 发起 SYN 攻击:

服务端执行如下命令,查看处于 SYN_RECV 状态的最大个数:
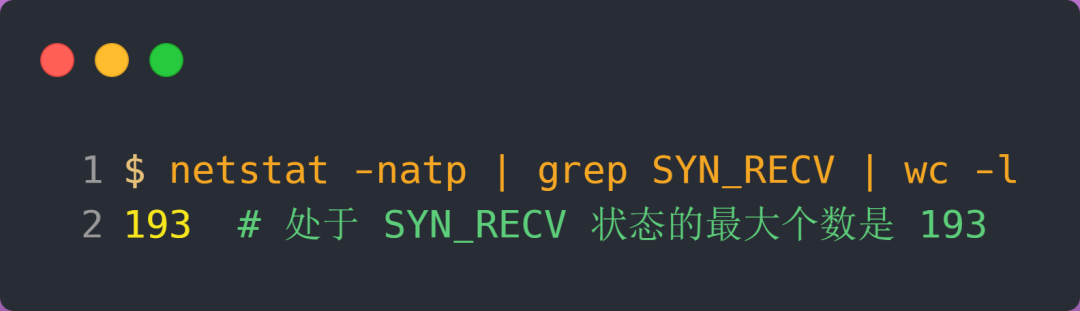
可以发现,服务端处于 SYN_RECV 状态的最大个数并不是 max_qlen_log 变量的值。
这就是前面所说的原因:如果当前半连接队列的长度 「没有超过」理论半连接队列最大值 max_qlen_log,那么如果条件 3 成立,则依然会丢弃 SYN 包,也就会使得服务端处于 SYN_REVC 状态的最大个数不会是理论值 max_qlen_log。
我们来分析一波条件 3 :
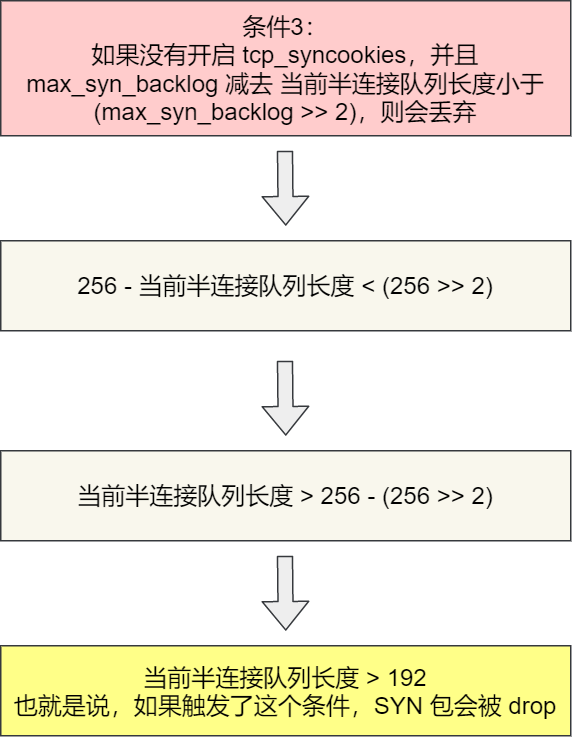
从上面的分析,可以得知如果触发「当前半连接队列长度 > 192」条件,TCP 第一次握手的 SYN 包是会被丢弃的。
在前面我们测试的结果,服务端处于 SYN_RECV 状态的最大个数是 193,正好是触发了条件 3,所以处于 SYN_RECV 状态的个数还没到「理论半连接队列最大值 256」,就已经把 SYN 包丢弃了。
所以,服务端处于 SYN_RECV 状态的最大个数分为如下两种情况:
- 如果「当前半连接队列」没超过「理论半连接队列最大值」,但是超过 max_syn_backlog - (max_syn_backlog >> 2),那么处于 SYN_RECV 状态的最大个数就是 max_syn_backlog - (max_syn_backlog >> 2);
- 如果「当前半连接队列」超过「理论半连接队列最大值」,那么处于 SYN_RECV 状态的最大个数就是「理论半连接队列最大值」;
每个 Linux 内核版本「理论」半连接最大值计算方式会不同。
在上面我们是针对 Linux 2.6.32 版本分析的「理论」半连接最大值的算法,可能每个版本有些不同。
比如在 Linux 5.0.0 的时候,「理论」半连接最大值就是全连接队列最大值,但依然还是有队列溢出的三个条件:
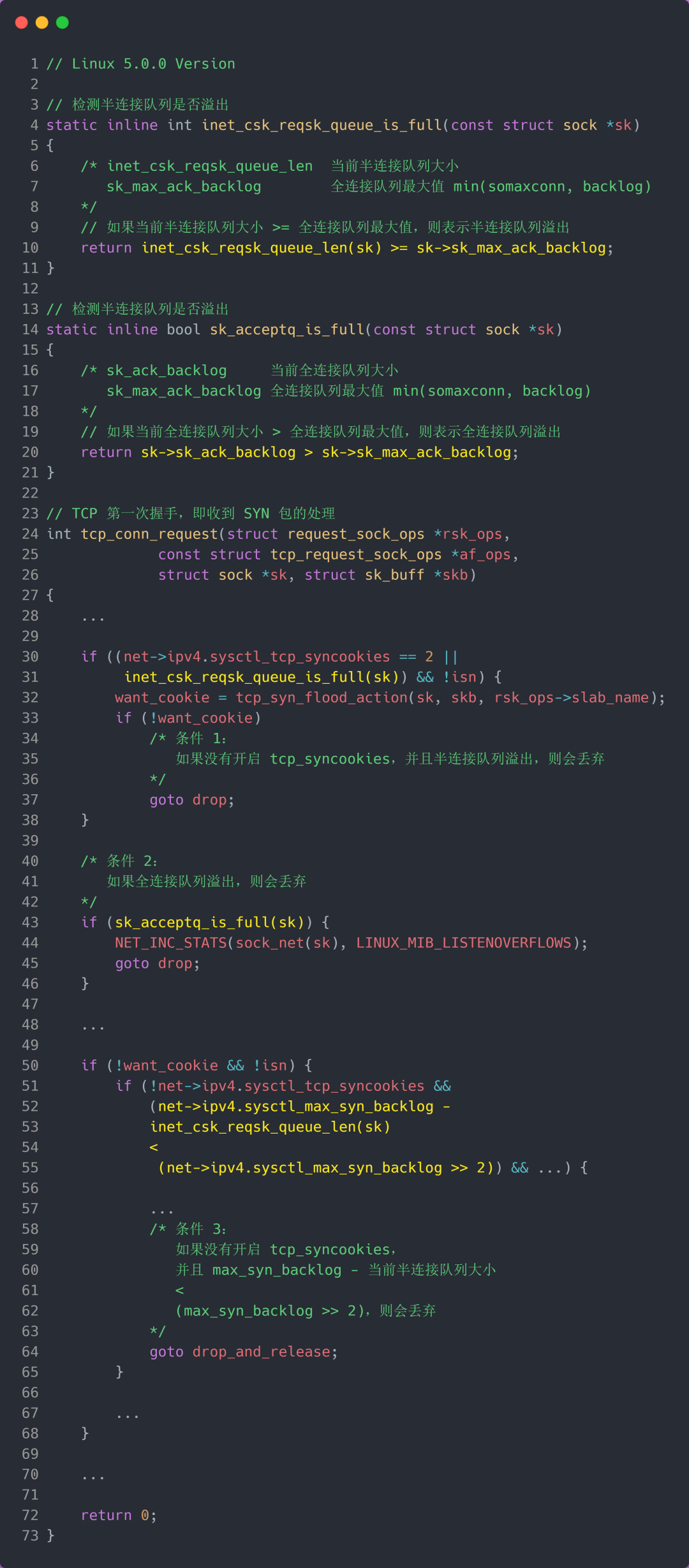
如果 SYN 半连接队列已满,只能丢弃连接吗?
并不是这样,开启 syncookies 功能就可以在不使用 SYN 半连接队列的情况下成功建立连接,在前面我们源码分析也可以看到这点,当开启了 syncookies 功能就不会丢弃连接。
syncookies 是这么做的:服务器根据当前状态计算出一个值,放在己方发出的 SYN+ACK 报文中发出,当客户端返回 ACK 报文时,取出该值验证,如果合法,就认为连接建立成功,如下图所示。
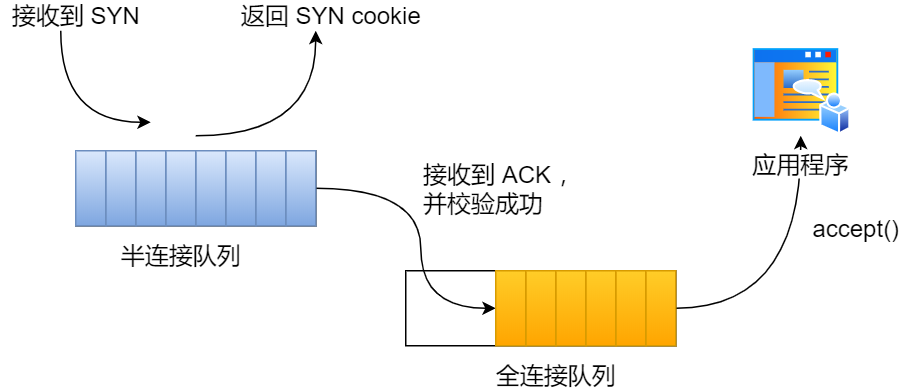 开启 syncookies 功能
开启 syncookies 功能
syncookies 参数主要有以下三个值:
- 0 值,表示关闭该功能;
- 1 值,表示仅当 SYN 半连接队列放不下时,再启用它;
- 2 值,表示无条件开启功能;
那么在应对 SYN 攻击时,只需要设置为 1 即可:

如何防御 SYN 攻击?
这里给出几种防御 SYN 攻击的方法:
- 增大半连接队列;
- 开启 tcp_syncookies 功能
- 减少 SYN+ACK 重传次数
方式一:增大半连接队列
在前面源码和实验中,得知要想增大半连接队列,我们得知不能只单纯增大 tcp_max_syn_backlog 的值,还需一同增大 somaxconn 和 backlog,也就是增大全连接队列。否则,只单纯增大 tcp_max_syn_backlog 是无效的。
增大 tcp_max_syn_backlog 和 somaxconn 的方法是修改 Linux 内核参数:
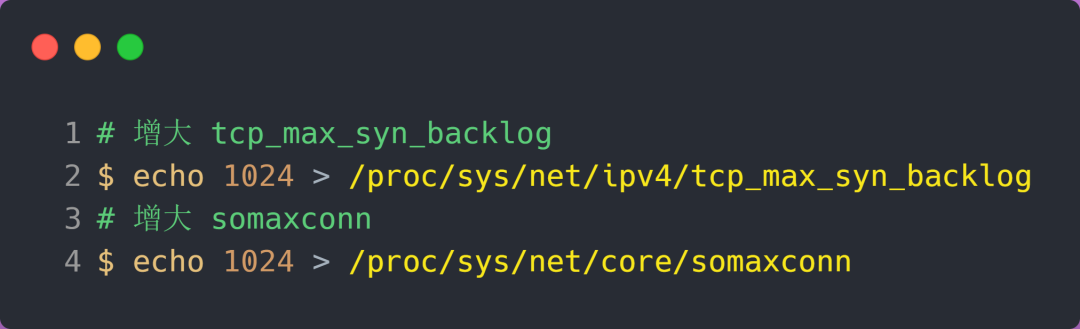
增大 backlog 的方式,每个 Web 服务都不同,比如 Nginx 增大 backlog 的方法如下:
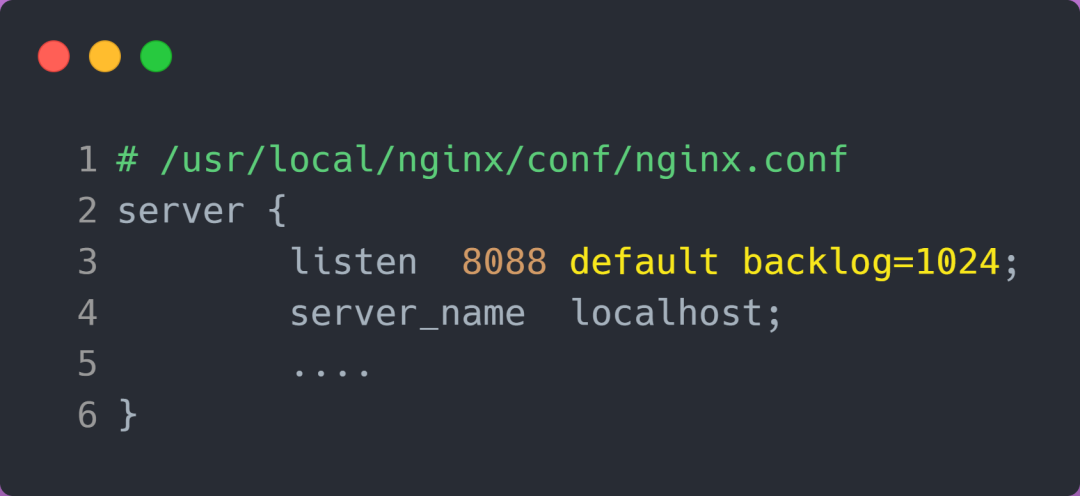
最后,改变了如上这些参数后,要重启 Nginx 服务,因为半连接队列和全连接队列都是在 listen() 初始化的。
方式二:开启 tcp_syncookies 功能
开启 tcp_syncookies 功能的方式也很简单,修改 Linux 内核参数:

方式三:减少 SYN+ACK 重传次数
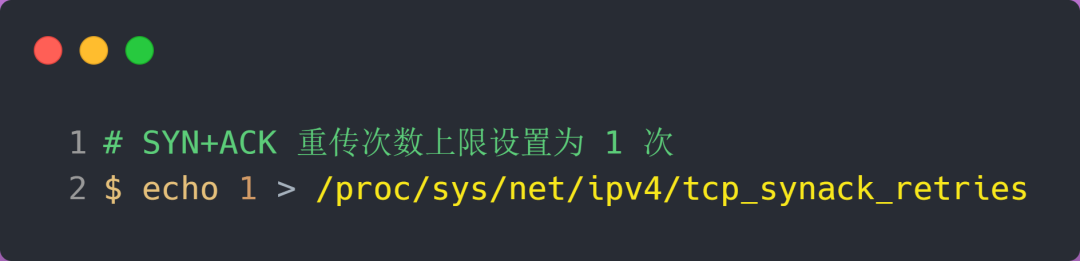
当服务端受到 SYN 攻击时,就会有大量处于 SYN_REVC 状态的 TCP 连接,处于这个状态的 TCP 会重传 SYN+ACK ,当重传超过次数达到上限后,就会断开连接。
那么针对 SYN 攻击的场景,我们可以减少 SYN+ACK 的重传次数,以加快处于 SYN_REVC 状态的 TCP 连接断开。
评论区